Uso de redes neuronales convolucionales para el reconocimiento de imágenes
Este artículo fue publicado originalmente en el sitio web de Cadence. Se reproduce aquí con el permiso de Cadence.
Las redes neuronales convolucionales (CNN) se utilizan ampliamente en problemas de reconocimiento de patrones e imágenes, ya que presentan una serie de ventajas en comparación con otras técnicas. Este libro blanco cubre los fundamentos de las CNN, incluyendo una descripción de las distintas capas utilizadas. Utilizando el reconocimiento de señales de tráfico como ejemplo, se discuten los retos del problema general y se presentan los algoritmos y el software de implementación desarrollados por Cadence que pueden compensar la carga computacional y la energía con una modesta degradación de las tasas de reconocimiento de señales. Describimos los retos que plantea el uso de las CNN en los sistemas embebidos y presentamos las características clave del procesador digital de señales (DSP) Cadence® Tensilica® Vision P5 para imagen y visión por ordenador y el software que lo hacen tan adecuado para las aplicaciones de CNN en muchas tareas de imagen y reconocimiento relacionadas.
¿Qué es una CNN?
Una red neuronal es un sistema de «neuronas» artificiales interconectadas que intercambian mensajes entre sí. Las conexiones tienen pesos numéricos que se ajustan durante el proceso de entrenamiento, de modo que una red adecuadamente entrenada responderá correctamente cuando se le presente una imagen o un patrón para reconocer. La red está formada por varias capas de «neuronas» que detectan características. Cada capa tiene muchas neuronas que responden a diferentes combinaciones de entradas de las capas anteriores. Como se muestra en la Figura 1, las capas se construyen de manera que la primera capa detecta un conjunto de patrones primitivos en la entrada, la segunda capa detecta patrones de patrones, la tercera capa detecta patrones de esos patrones, y así sucesivamente. Las CNN típicas utilizan de 5 a 25 capas distintas de reconocimiento de patrones.
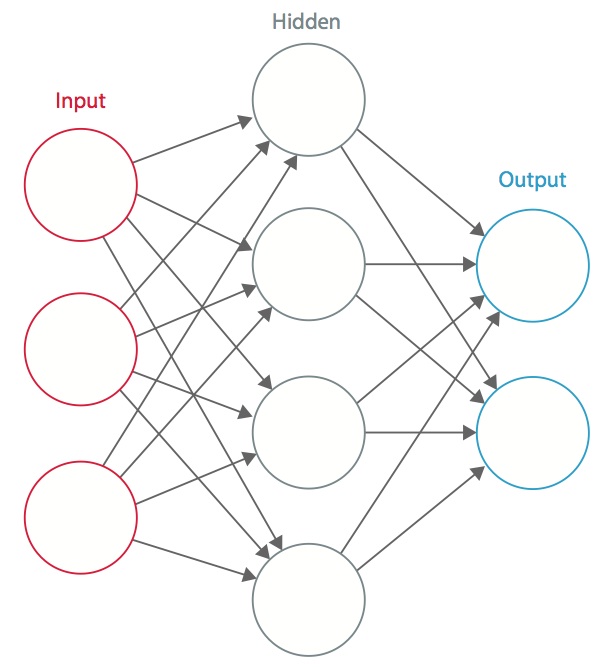
Figura 1: Una red neuronal artificial
El entrenamiento se realiza utilizando un conjunto de datos «etiquetados» de entradas en un amplio surtido de patrones de entrada representativos que se etiquetan con su respuesta de salida prevista. El entrenamiento utiliza métodos de propósito general para determinar iterativamente los pesos de las neuronas de características intermedias y finales. La figura 2 muestra el proceso de entrenamiento a nivel de bloques.
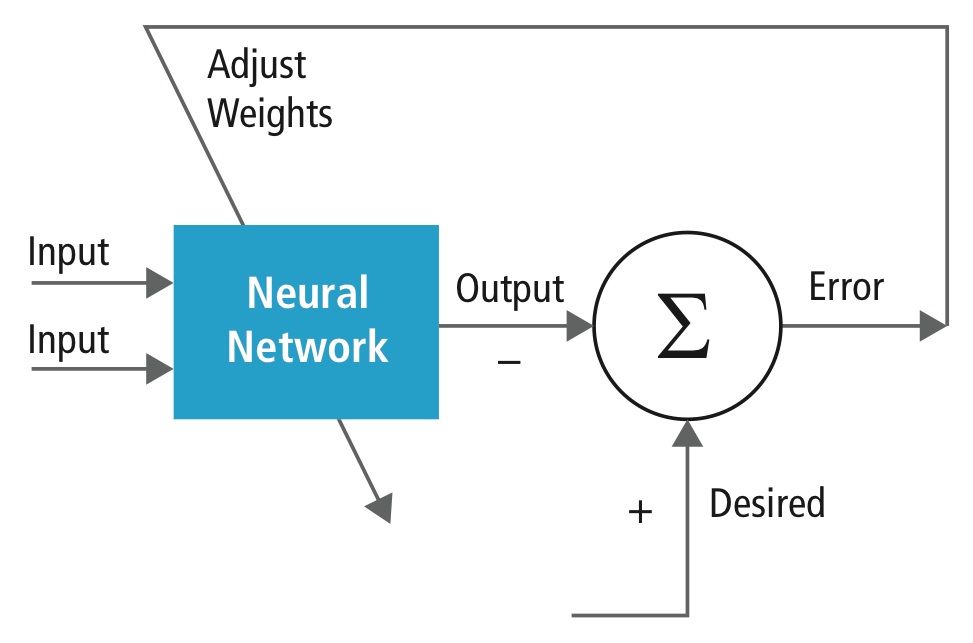
Figura 2: Entrenamiento de redes neuronales
Las redes neuronales se inspiran en los sistemas neuronales biológicos. La unidad computacional básica del cerebro es una neurona y están conectadas con sinapsis. La figura 3 compara una neurona biológica con un modelo matemático básico .


Figura 3: Ilustración de una neurona biológica (arriba) y su modelo matemático (abajo)
En un sistema neuronal animal real, se percibe que una neurona recibe señales de entrada desde sus dendritas y produce señales de salida a lo largo de su axón. El axón se ramifica y se conecta mediante sinapsis a las dendritas de otras neuronas. Cuando la combinación de señales de entrada alcanza alguna condición de umbral entre sus dendritas de entrada, la neurona se activa y su activación se comunica a las neuronas sucesoras.
En el modelo computacional de la red neuronal, las señales que viajan a lo largo de los axones (por ejemplo, x0) interactúan multiplicativamente (por ejemplo, w0x0) con las dendritas de la otra neurona en función de la fuerza sináptica en esa sinapsis (por ejemplo, w0). Los pesos sinápticos son aprendibles y controlan la influencia de una u otra neurona. Las dendritas llevan la señal al cuerpo celular, donde se suman todas. Si la suma final está por encima de un umbral especificado, la neurona se dispara, enviando un pico a lo largo de su axón. En el modelo computacional, se supone que los tiempos precisos de los disparos no importan y que sólo la frecuencia de los disparos comunica la información. Basándose en la interpretación del código de velocidad, la frecuencia de disparo de la neurona se modela con una función de activación ƒ que representa la frecuencia de los picos a lo largo del axón. Una elección común de la función de activación es la sigmoidea. En resumen, cada neurona calcula el producto punto de las entradas y los pesos, añade el sesgo y aplica la no linealidad como función de activación (por ejemplo, siguiendo una función de respuesta sigmoidea).
Una CNN es un caso especial de la red neuronal descrita anteriormente. Una CNN consta de una o más capas convolucionales, a menudo con una capa de submuestreo, que van seguidas de una o más capas totalmente conectadas como en una red neuronal estándar.
El diseño de una CNN está motivado por el descubrimiento de un mecanismo visual, la corteza visual, en el cerebro. La corteza visual contiene una gran cantidad de células que se encargan de detectar la luz en pequeñas subregiones superpuestas del campo visual, que se denominan campos receptivos. Estas células actúan como filtros locales sobre el espacio de entrada, y las células más complejas tienen campos receptivos más grandes. La capa de convolución de una CNN realiza la función que llevan a cabo las células de la corteza visual.
En la figura 4 se muestra una CNN típica para reconocer señales de tráfico. Cada característica de una capa recibe entradas de un conjunto de características localizadas en una pequeña vecindad en la capa anterior llamada campo receptivo local. Con los campos receptivos locales, las características pueden extraer rasgos visuales elementales, como bordes orientados, puntos finales, esquinas, etc., que luego son combinados por las capas superiores.
En el modelo tradicional de reconocimiento de patrones/imágenes, un extractor de rasgos diseñado a mano recoge la información relevante de la entrada y elimina las variabilidades irrelevantes. Al extractor le sigue un clasificador entrenable, una red neuronal estándar que clasifica los vectores de características en clases.
En una CNN, las capas de convolución desempeñan el papel de extractor de características. Pero no están diseñadas a mano. Los pesos del núcleo del filtro de convolución se deciden como parte del proceso de entrenamiento. Las capas convolucionales son capaces de extraer las características locales porque restringen los campos receptivos de las capas ocultas para que sean locales.
Figura 4: Diagrama de bloques típico de una CNN
Las CNN se utilizan en diversas áreas, como el reconocimiento de imágenes y patrones, el reconocimiento del habla, el procesamiento del lenguaje natural y el análisis de vídeo. Hay varias razones por las que las redes neuronales convolucionales están adquiriendo importancia. En los modelos tradicionales de reconocimiento de patrones, los extractores de características se diseñan a mano. En las CNN, los pesos de la capa convolucional que se utiliza para la extracción de características y de la capa totalmente conectada que se utiliza para la clasificación se determinan durante el proceso de entrenamiento. Las estructuras de red mejoradas de las CNN permiten ahorrar en requisitos de memoria y complejidad de cálculo y, al mismo tiempo, ofrecen un mejor rendimiento para aplicaciones en las que la entrada tiene correlación local (por ejemplo, imagen y habla).
Los grandes requisitos de recursos computacionales para el entrenamiento y la evaluación de las CNN se satisfacen a veces mediante unidades de procesamiento gráfico (GPU), DSP u otras arquitecturas de silicio optimizadas para obtener un alto rendimiento y un bajo consumo de energía cuando se ejecutan los patrones idiosincrásicos del cálculo de las CNN. De hecho, procesadores avanzados como el DSP Tensilica Vision P5 for Imaging and Computer Vision de Cadence tienen un conjunto casi ideal de recursos de computación y memoria necesarios para ejecutar CNNs con alta eficiencia.
En aplicaciones de reconocimiento de patrones e imágenes, las mejores tasas de detección correcta (CDRs) se han logrado utilizando CNNs. Por ejemplo, las CNN han logrado una CDR del 99,77% utilizando la base de datos MNIST de dígitos manuscritos , una CDR del 97,47% con el conjunto de datos NORB de objetos 3D , y una CDR del 97,6% en ~5600 imágenes de más de 10 objetos . Las CNN no sólo ofrecen el mejor rendimiento en comparación con otros algoritmos de detección, sino que incluso superan a los humanos en casos como la clasificación de objetos en categorías de grano fino, como la raza particular de un perro o la especie de un pájaro.
La figura 5 muestra una canalización típica de algoritmos de visión, que consta de cuatro etapas: preprocesamiento de la imagen, detección de regiones de interés (ROI) que contienen objetos probables, reconocimiento de objetos y toma de decisiones de visión. La etapa de preprocesamiento suele depender de los detalles de la entrada, especialmente del sistema de cámaras, y a menudo se implementa en una unidad de cableado fuera del subsistema de visión. La toma de decisiones al final del pipeline suele operar sobre los objetos reconocidos; puede tomar decisiones complejas, pero opera con muchos menos datos, por lo que estas decisiones no suelen ser problemas computacionalmente difíciles o que requieran mucha memoria. El gran reto está en las etapas de detección y reconocimiento de objetos, donde las CNN están teniendo ahora un amplio impacto.

Figura 5: Pipeline de algoritmos de visión
Capas de CNN
Al apilar múltiples y diferentes capas en una CNN, se construyen arquitecturas complejas para problemas de clasificación. Cuatro tipos de capas son los más comunes: capas de convolución, capas de agrupación/submuestreo, capas no lineales y capas totalmente conectadas.
Capas de convolución
La operación de convolución extrae diferentes características de la entrada. La primera capa de convolución extrae características de bajo nivel como bordes, líneas y esquinas. Las capas de nivel superior extraen características de nivel superior. La figura 6 ilustra el proceso de convolución 3D utilizado en las CNN. La entrada es de tamaño N x N x D y se convoluciona con H kernels, cada uno de
tamaño k x k x D por separado. La convolución de una entrada con un núcleo produce una característica de salida, y con H núcleos independientemente produce H características. Empezando por la esquina superior izquierda de la entrada, cada núcleo se mueve de izquierda a derecha, un elemento cada vez. Una vez alcanzada la esquina superior derecha, el núcleo se mueve un elemento en dirección descendente, y de nuevo el núcleo se mueve de izquierda a derecha, un elemento cada vez. Este proceso se repite hasta que el núcleo alcanza la esquina inferior derecha. Para el caso en que N = 32 y k = 5 , hay 28 posiciones únicas de izquierda a derecha y 28 posiciones únicas de arriba a abajo que el núcleo puede tomar. En función de estas posiciones, cada característica de la salida contendrá 28×28 (es decir, (N-k+1) x (N-k+1)) elementos. Para cada posición del núcleo en un proceso de ventana deslizante, los elementos k x k x D de la entrada y los elementos k x k x D del núcleo se multiplican elemento por elemento y se acumulan. Por lo tanto, para crear un elemento de una característica de salida, se requieren k x k x D operaciones de multiplicación-acumulación.
Figura 6: Representación pictórica del proceso de convolución
Capas de agrupamiento/submuestreo
La capa de agrupamiento/submuestreo reduce la resolución de las características. Hace que las características sean robustas contra el ruido y la distorsión. Hay dos formas de realizar el pooling: el pooling máximo y el pooling medio. En ambos casos, la entrada se divide en espacios bidimensionales no superpuestos. Por ejemplo, en la figura 4, la capa 2 es la capa de pooling. Cada característica de entrada es de 28×28 y se divide en 14×14 regiones de tamaño 2×2. Para el pooling medio, se calcula la media de los cuatro valores de la región. Para el pooling máximo, se selecciona el valor máximo de los cuatro valores.
La figura 7 detalla el proceso de pooling. La entrada es de tamaño 4×4. Para el submuestreo 2×2, una imagen de 4×4 se divide en cuatro matrices no superpuestas de tamaño 2×2. En el caso del max pooling, el valor máximo de los cuatro valores de la matriz 2×2 es la salida. En el caso de la agrupación media, la salida es la media de los cuatro valores. Tenga en cuenta que para la salida con índice (2,2), el resultado del promedio es una fracción que ha sido redondeada al entero más cercano.
Figura 7: Representación pictórica de la agrupación máxima y la agrupación media
Capas no lineales
Las redes neuronales en general y las CNN en particular se basan en una función de «activación» no lineal para señalar la identificación distinta de las características probables en cada capa oculta. Las CNN pueden utilizar una variedad de funciones específicas -como las unidades lineales rectificadas (ReLU) y las funciones de disparo continuas (no lineales)- para implementar eficazmente este disparo no lineal.
ReLU
Una ReLU implementa la función y = max(x,0), por lo que los tamaños de entrada y salida de esta capa son los mismos. Aumenta las propiedades no lineales de la función de decisión y de la red global sin afectar a los campos receptivos de la capa de convolución. En comparación con otras funciones no lineales utilizadas en las CNN (por ejemplo, la tangente hiperbólica, el absoluto de la tangente hiperbólica y la sigmoidea), la ventaja de una ReLU es que la red se entrena muchas veces más rápido. La funcionalidad de ReLU se ilustra en la Figura 8, con su función de transferencia trazada sobre la flecha.
Figura 8: Representación pictórica de la funcionalidad de ReLU
Función de disparo continua (no lineal)
La capa no lineal opera elemento a elemento en cada característica. Una función de disparo continua puede ser la tangente hiperbólica (Figura 9), el absoluto de la tangente hiperbólica (Figura 10) o la sigmoidea (Figura 11). La figura 12 demuestra cómo se aplica la no linealidad elemento por elemento.
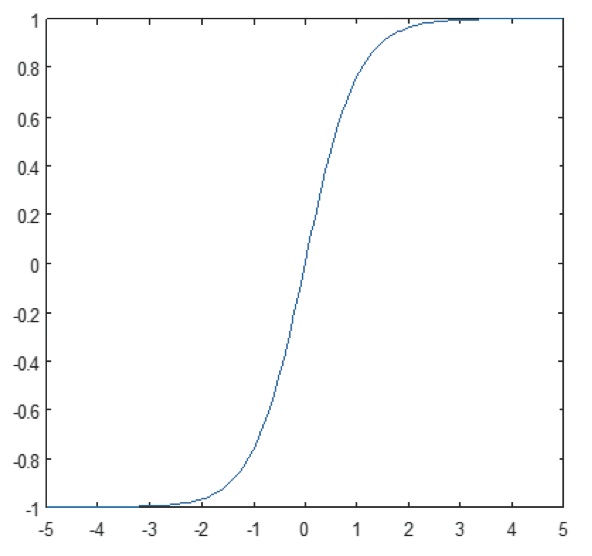
Figura 9: Gráfico de la función tangente hiperbólica
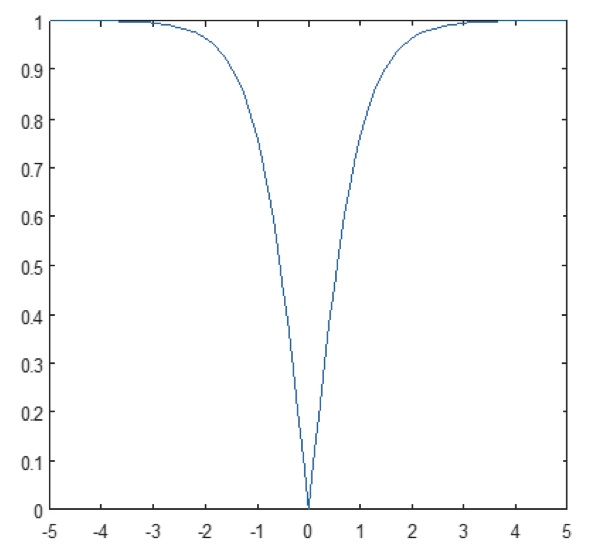
Figura 10: Gráfico del absoluto de la función tangente hiperbólica
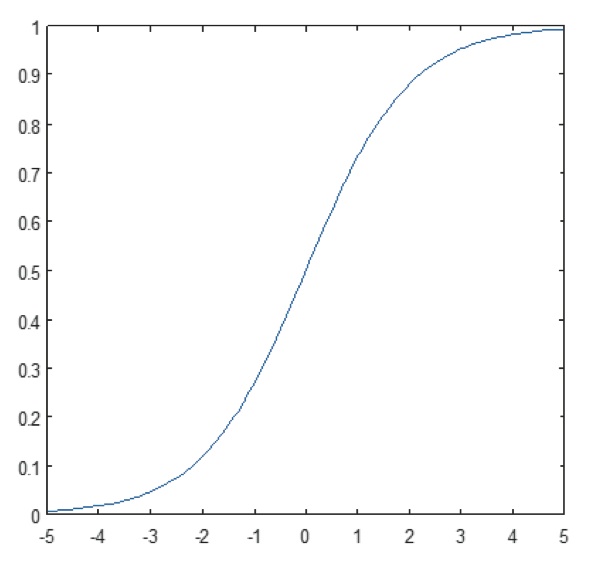
Figura 11: Trazado de la función sigmoidea
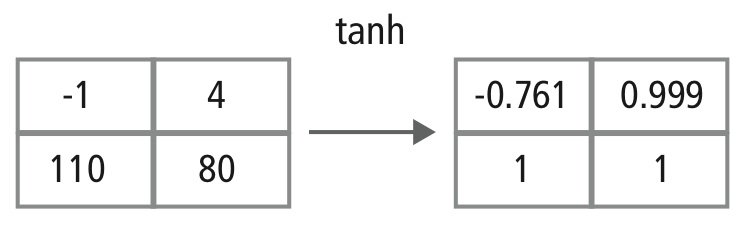
Figura 12: Representación pictórica del procesamiento de tanh
Capas totalmente conectadas
Las capas totalmente conectadas se suelen utilizar como capas finales de una CNN. Estas capas suman matemáticamente una ponderación de la capa anterior de características, indicando la mezcla precisa de «ingredientes» para determinar un resultado de salida específico. En el caso de una capa totalmente conectada, todos los elementos de todas las características de la capa anterior se utilizan en el cálculo de cada elemento de cada característica de salida.
La figura 13 explica la capa totalmente conectada L. La capa L-1 tiene dos características, cada una de las cuales es 2×2, es decir, tiene cuatro elementos. La capa L tiene dos características, cada una de las cuales tiene un solo elemento.
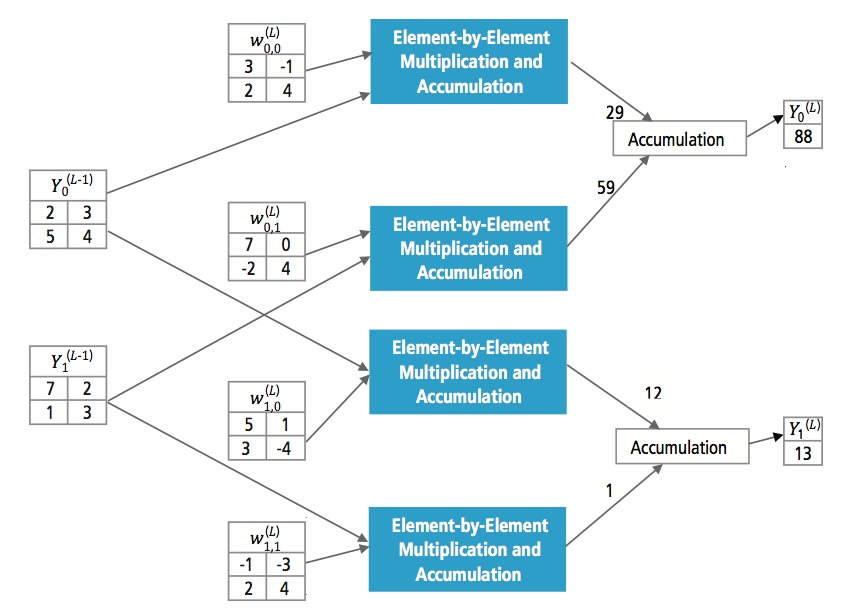
Figura 13: Procesamiento de una capa totalmente conectada
¿Por qué CNN?
Aunque las redes neuronales y otros métodos de detección de patrones han existido durante los últimos 50 años, ha habido un desarrollo significativo en el área de las redes neuronales convolucionales en el pasado reciente. Esta sección cubre las ventajas de utilizar CNN para el reconocimiento de imágenes.
Resistencia a los cambios y a la distorsión de la imagen
La detección mediante CNN es resistente a distorsiones como el cambio de forma debido a la lente de la cámara, diferentes condiciones de iluminación, diferentes poses, presencia de oclusiones parciales, desplazamientos horizontales y verticales, etc. Sin embargo, las CNN son invariables a los cambios, ya que se utiliza la misma configuración de pesos en todo el espacio. En teoría, también podemos conseguir la invariabilidad de los cambios utilizando capas totalmente conectadas. Pero el resultado del entrenamiento en este caso son múltiples unidades con patrones de peso idénticos en diferentes lugares de la entrada. Para aprender estas configuraciones de peso, se necesitaría un gran número de instancias de entrenamiento para cubrir el espacio de posibles variaciones.
Menos requisitos de memoria
En este mismo caso hipotético en el que utilizamos una capa totalmente conectada para extraer las características, la imagen de entrada de tamaño 32×32 y una capa oculta que tenga 1000 características requerirá un orden de 106 coeficientes, un requisito de memoria enorme. En la capa convolucional, se utilizan los mismos coeficientes en diferentes lugares del espacio, por lo que el requisito de memoria se reduce drásticamente.
Entrenamiento más fácil y mejor
También utilizando la red neuronal estándar que sería equivalente a una CNN, ya que el número de parámetros sería mucho mayor, el tiempo de entrenamiento también aumentaría proporcionalmente. En una CNN, como el número de parámetros se reduce drásticamente, el tiempo de entrenamiento se reduce proporcionalmente. Además, suponiendo un entrenamiento perfecto, podemos diseñar una red neuronal estándar cuyo rendimiento sería el mismo que el de una CNN. Pero en el entrenamiento práctico,
una red neuronal estándar equivalente a la CNN tendría más parámetros, lo que llevaría a una mayor adición de ruido durante el proceso de entrenamiento. Por lo tanto, el rendimiento de una red neuronal estándar equivalente a una CNN siempre será más pobre.
Algoritmo de reconocimiento para el conjunto de datos GTSRB
El German Traffic Sign Recognition Benchmark (GTSRB) fue un desafío de clasificación multiclase y de una sola imagen celebrado en la International Joint Conference on Neural Networks (IJCNN) 2011, con los siguientes requisitos:
- 51.840 imágenes de señales de tráfico alemanas en 43 clases (Figuras 14 y 15)
- El tamaño de las imágenes varía de 15×15 a 222×193
- Las imágenes se agrupan por clase y pista con al menos 30 imágenes por pista
- Las imágenes están disponibles como imágenes en color (RGB), características HOG, características Haar e histogramas de color
- La competencia es sólo para el algoritmo de clasificación; el algoritmo para encontrar la región de interés en el marco no es necesario
- La información temporal de las secuencias de prueba no se comparte, por lo que la dimensión temporal no se puede utilizar en el algoritmo de clasificación

Figura 14: Señales de tráfico ideales de GTSRB

Figura 15: Señales de tráfico de GTSRB con deficiencias
Algoritmo de Cadence para el reconocimiento de señales de tráfico en el conjunto de datos de GTSRB
Cadence ha desarrollado varios algoritmos en MATLAB para el reconocimiento de señales de tráfico utilizando el conjunto de datos de GTSRB, comenzando con una configuración de referencia basada en un conocido artículo sobre reconocimiento de señales . La tasa de detección correcta del 99,24% y el esfuerzo de cálculo de casi >50 millones de multiplicaciones por señal se muestra como un punto verde grueso en la Figura 16. Cadence ha logrado resultados significativamente mejores utilizando nuestro nuevo enfoque de CNN jerárquica. En este algoritmo, las 43 señales de tráfico se han dividido en cinco familias. En total, implementamos seis CNN más pequeñas. La primera CNN decide a qué familia pertenece la señal de tráfico recibida. Una vez conocida la familia de la señal, se ejecuta la CNN (una de las cinco restantes) correspondiente a la familia detectada para decidir la señal de tráfico dentro de esa familia. Utilizando este algoritmo, Cadence ha conseguido una tasa de detección correcta del 99,58%, la mejor CDR conseguida en GTSRB hasta la fecha.
Algoritmo para el equilibrio entre rendimiento y complejidad
Con el fin de controlar la complejidad de las CNN en las aplicaciones embebidas, Cadence también ha desarrollado un algoritmo propio que utiliza la descomposición de valores propios que reduce una CNN entrenada a su dimensión canónica. Utilizando este algoritmo, hemos sido capaces de reducir drásticamente la complejidad de la CNN sin ninguna degradación del rendimiento, o con una pequeña reducción controlada del CDR. La figura 16 muestra los resultados obtenidos:
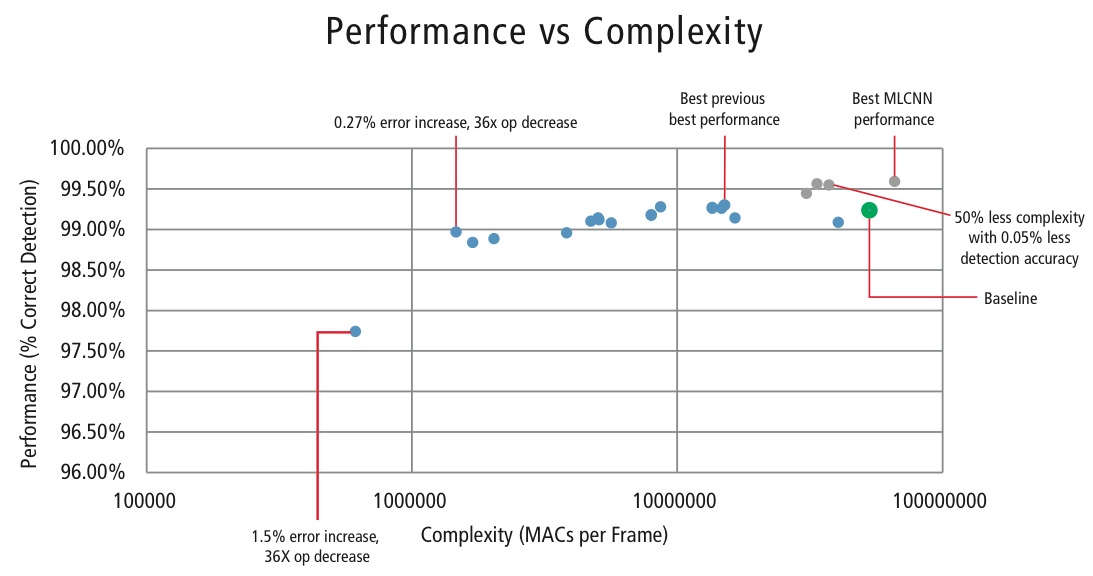
Figura 16: Gráfico de rendimiento frente a complejidad para varias configuraciones de CNN para detectar señales de tráfico en el conjunto de datos GTSRB
El punto verde de la figura 16 es la configuración de referencia. Esta configuración se acerca bastante a la sugerida en la Referencia . Requiere 53 MMACs por trama para una tasa de error del 0,76%.
- El segundo punto desde la izquierda requiere 1,47 millones de MACs por trama para una tasa de error del 1,03%, es decir, para un aumento de la tasa de error del 0,27%, el requisito de MAC se ha reducido en un factor de 36,14.
- El punto más a la izquierda requiere 0,61 MMACs por trama para lograr una tasa de error del 2,26%, es decir, el número de MACs se reduce en un factor de 86,4 veces.
- Los puntos en azul son para una CNN de un solo nivel, mientras que los puntos en rojo son para una CNN jerárquica. La CNN jerárquica alcanza un rendimiento del 99,58% en el mejor de los casos.
CNNs en sistemas embebidos
Como se muestra en la figura 5, un subsistema de visión requiere mucho procesamiento de imágenes además de una CNN. Para ejecutar CNNs en un sistema embebido de potencia limitada que soporte el procesamiento de imágenes, debe cumplir los siguientes requisitos:
- Disponibilidad de alto rendimiento computacional: Para una implementación típica de CNN, el requisito es que se realicen miles de millones de MACs por segundo.
- Mayor ancho de banda de carga/almacenamiento: En el caso de una capa totalmente conectada utilizada para la clasificación, cada coeficiente se utiliza en la multiplicación sólo una vez. Por lo tanto, el requisito de ancho de banda de carga-almacenamiento es mayor que el número de MAC que realiza el procesador.
- Requerimiento de energía dinámica baja: El sistema debe consumir menos energía. Para abordar esta cuestión, se requiere una implementación de punto fijo, que impone el requisito de cumplir los requisitos de rendimiento utilizando el mínimo número posible de bits.
- Flexibilidad: Debe ser posible actualizar fácilmente el diseño existente a un nuevo diseño de mejor rendimiento.
Dado que los recursos computacionales son siempre una limitación en los sistemas embebidos, si el caso de uso permite una pequeña degradación en el rendimiento, es útil tener un algoritmo que pueda lograr un gran ahorro en la complejidad computacional a costa de una pequeña degradación controlada en el rendimiento. Por lo tanto, el trabajo de Cadence en un algoritmo para lograr la complejidad frente a una compensación de rendimiento, como se explica en la sección anterior, tiene una gran relevancia para la implementación de CNNs en sistemas embebidos.
CNNs en procesadores Tensilica
El DSP Tensilica Vision P5 es un DSP de alto rendimiento y bajo consumo diseñado específicamente para el procesamiento de imágenes y visión por ordenador. El DSP tiene una arquitectura VLIW con soporte SIMD. Dispone de cinco ranuras de emisión en una palabra de instrucción de hasta 96 bits y puede cargar hasta palabras de 1024 bits de la memoria en cada ciclo. Los registros internos y las unidades de operación van de 512 bits a 1536 bits, donde los datos se representan como 16, 32 o 64 rebanadas de datos de 8b, 16b, 24b, 32b o 48b de píxeles.
El DSP aborda todos los retos para la implementación de CNNs en sistemas embebidos como se ha comentado en la sección anterior.
- Disponibilidad de alto rendimiento computacional: Además del soporte avanzado para implementar el procesamiento de señales de imagen, el DSP tiene soporte de instrucciones para todas las etapas de las CNNs. Para las operaciones de convolución, dispone de un conjunto de instrucciones muy rico que admite operaciones de multiplicación/multiplicación-acumulación de 8b x 8b, 8b x 16b y 16b x 16b para datos con/sin signo. Puede realizar hasta 64 operaciones de multiplicación/acumulación de 8b x 16b y 8b x 8b en un ciclo y 32 operaciones de multiplicación/acumulación de 16b x 16b en un ciclo. Para la funcionalidad de pooling máximo y ReLU, el DSP dispone de instrucciones para realizar 64 comparaciones de 8 bits en un ciclo. Para implementar funciones no lineales con rangos finitos como tanh y signum, dispone de instrucciones para implementar una tabla de búsqueda para 64 valores de 7 bits en un ciclo. En la mayoría de los casos, las instrucciones de comparación y tabla de consulta se programan en paralelo con las instrucciones de multiplicación/multiplicación-acumulación y no requieren ciclos adicionales.
- Mayor ancho de banda de carga/almacenamiento: el DSP puede realizar hasta dos operaciones de carga/almacenamiento de 512 bits por ciclo.
- Baja demanda de energía dinámica: El DSP es una máquina de punto fijo. Debido al manejo flexible de una variedad de tipos de datos, se puede lograr el rendimiento completo y la ventaja energética de la computación mixta de 16b y 8b con una pérdida mínima de precisión.
- Flexibilidad: Dado que el DSP es un procesador programable, el sistema puede actualizarse a una nueva versión simplemente realizando una actualización del firmware.
- Punto flotante: Para los algoritmos que requieren un rango dinámico ampliado para sus datos y/o coeficientes, el DSP dispone de una unidad opcional de punto flotante vectorial.
El DSP Vision P5 se entrega con un completo conjunto de herramientas de software que incluye un compilador C/C++ de alto rendimiento con vectorización y programación automáticas para soportar la arquitectura SIMD y VLIW sin necesidad de escribir lenguaje ensamblador. Este completo conjunto de herramientas también incluye el enlazador, el ensamblador, el depurador, el perfilador y las herramientas de visualización gráfica. Un completo simulador de conjuntos de instrucciones (ISS) permite al diseñador simular y evaluar rápidamente el rendimiento. Cuando se trabaja con grandes sistemas o largos vectores de prueba, la opción del simulador rápido y funcional TurboXim alcanza velocidades entre 40 y 80 veces más rápidas que el ISS para un desarrollo de software y una verificación funcional eficientes.
Cadence ha implementado una arquitectura de una sola capa CNN en el DSP para el reconocimiento de señales de tráfico alemanas. Cadence ha logrado un CDR del 99,403% con una cuantificación de 16 bits para las muestras de datos y de 8 bits para los coeficientes en todas las capas de esta arquitectura. Tiene dos capas de convolución, tres capas totalmente conectadas, cuatro capas ReLU, tres capas de agrupación máxima y una capa no lineal tanh. Cadence ha logrado un rendimiento de 38,58 MACs/ciclo de media para la red completa, incluyendo los ciclos de todas las capas de max pooling, tanh y ReLU. Cadence ha conseguido un rendimiento en el mejor de los casos de 58,43 MACs por ciclo para la tercera capa, incluyendo los ciclos para las funcionalidades tanh y ReLU. Este DSP que funciona a 600 MHz puede procesar más de 850 señales de tráfico en un segundo.
El futuro de las CNN
Entre las áreas más prometedoras de la investigación en redes neuronales se encuentran las redes neuronales recurrentes (RNN) que utilizan la memoria a corto plazo (LSTM). Estas áreas están proporcionando el estado actual de la técnica en tareas de reconocimiento de series temporales como el reconocimiento del habla y el reconocimiento de la escritura a mano. Las RNN/autocodificadores también son capaces de generar escritura a mano/voz/imágenes con alguna distribución conocida ,,,,.
Las redes de creencia profunda, otro tipo prometedor de red que utiliza máquinas de Boltzman restringidas (RMBs)/autocodificadores, son capaces de ser entrenadas con avidez, una capa a la vez, y por lo tanto son más fácilmente entrenables para redes muy profundas ,.
Conclusión
LasCNNs dan el mejor rendimiento en problemas de reconocimiento de patrones/imágenes e incluso superan a los humanos en ciertos casos. Cadence ha conseguido los mejores resultados de la industria utilizando algoritmos y arquitecturas propias con CNNs. Hemos desarrollado CNNs jerárquicas para el reconocimiento de señales de tráfico en el GTSRB, logrando el mejor rendimiento jamás obtenido en este conjunto de datos. Hemos desarrollado otro algoritmo para el equilibrio entre rendimiento y complejidad y hemos sido capaces de lograr una reducción de la complejidad en un factor de 86 para una degradación del CDR de menos del 2%. El DSP Tensilica Vision P5 para imagen y visión por ordenador de Cadence tiene todas las características necesarias para implementar CNNs además de las características necesarias para hacer el procesamiento de señales de imagen. Se pueden realizar más de 850 reconocimientos de señales de tráfico ejecutando el DSP a 600MHz. El DSP Tensilica Vision P5 de Cadence tiene un conjunto de características casi ideal para ejecutar CNNs.
«Red neuronal artificial». Wikipedia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. «Redes neuronales parte 1: configuración de la arquitectura». Apuntes para CS231n Redes neuronales convolucionales para el reconocimiento visual, Universidad de Stanford. http://cs231n.github.io/neural-networks-1/
«Red neuronal convolucional». Wikipedia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, y Yann LeCun. 2011. «Reconocimiento de señales de tráfico con redes multiescala». Instituto Courant de Ciencias Matemáticas, Universidad de Nueva York. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, y Jürgen Schmidhuber. 2012. «Redes neuronales profundas multicolumnas para la clasificación de imágenes». 2012 IEEE Conference on Computer Vision and Pattern Recognition (Nueva York, NY: Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, y Jurgen Schmidhuber. 2011. «Redes neuronales convolucionales flexibles y de alto rendimiento para la clasificación de imágenes». Actas de la Vigésimo Segunda Conferencia Internacional Conjunta sobre Inteligencia Artificial-Volumen Dos: 1237-1242. Recuperado el 17 de noviembre de 2013. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, y Andrew D. Back. 1997. «Face Recognition: A Convolutional Neural Network Approach». IEEE Transactions on Neural Networks, Volume 8; Issue 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. «Desafío de reconocimiento visual a gran escala de ImageNet». International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. Feb 22, 2015. «Aceleración de redes convolucionales profundas mediante hardware especializado». Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen y C. Igel. «Man Vs. Computer: Benchmarking Machine Learning Algorithms For Traffic Sign Application». IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, y Jürgen Schmidhuber. 1997. «Memoria a largo plazo». Neural Computation, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. «Generando secuencias con redes neuronales recurrentes». http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. «Redes neuronales recurrentes». http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., y David J. Field. 1996. «Emergencia de las propiedades del campo receptivo de las células simples mediante el aprendizaje de un código disperso para las imágenes naturales». Nature 381.6583: 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. y Salakhutdinov, R. R. 2006. «Reducción de la dimensionalidad de los datos con redes neuronales». Science vol. 313 no. 5786 pp. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. «Redes de creencias profundas». Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks