Tutorial de Big Data y el Ecosistema Hadoop
Bienvenidos a la primera lección ‘Big Data y el Ecosistema Hadoop’ del tutorial de Big Data Hadoop que forma parte del ‘Curso de Certificación de Big Data Hadoop y Spark Developer’ ofrecido por Simplilearn. Esta lección es una introducción al ecosistema de Big Data y Hadoop. En la siguiente sección, discutiremos los objetivos de esta lección.
Objetivos
Después de completar esta lección, serás capaz de:
-
Entender el concepto de Big Data y sus retos
-
Explicar qué es Big Data
-
Explicar qué es Hadoop y cómo aborda los retos de Big Data
-
Describa el ecosistema Hadoop
Veamos ahora una visión general de Big Data y Hadoop.
Resumen de Big Data y Hadoop
Antes del año 2000, los datos eran relativamente pequeños de lo que son actualmente; sin embargo, el cálculo de datos era complejo. Todo el cómputo de datos dependía de la capacidad de procesamiento de los ordenadores disponibles.
Más tarde, a medida que los datos crecían, la solución era tener ordenadores con gran memoria y procesadores rápidos. Sin embargo, después del año 2000, los datos siguieron creciendo y la solución inicial ya no podía servir.
En los últimos años, se ha producido una increíble explosión en el volumen de datos. IBM informó de que en 2012 se generaron 2,5 exabytes, o 2.500 millones de gigabytes, de datos cada día.
Aquí hay algunas estadísticas que indican la proliferación de datos de Forbes, septiembre de 2015. Cada segundo se realizan 40.000 consultas de búsqueda en Google. Hasta 300 horas de vídeo se suben a YouTube cada minuto.
En Facebook, los usuarios envían 31,25 millones de mensajes y se ven 2,77 millones de vídeos cada minuto. En 2017, casi el 80% de las fotos se tomarán con teléfonos inteligentes.
En 2020, al menos un tercio de todos los datos pasarán por la nube (una red de servidores conectados a través de Internet). Para el año 2020, se crearán unos 1,7 megabytes de información nueva cada segundo por cada ser humano del planeta.
Los datos están creciendo más rápido que nunca. Se pueden utilizar más ordenadores para gestionar estos datos en constante crecimiento. En lugar de que una máquina realice el trabajo, puedes utilizar varias máquinas. Esto se llama un sistema distribuido.
¡Puedes consultar el avance del curso de certificación Big Data Hadoop y Spark Developer aquí!
Veamos un ejemplo para entender cómo funciona un sistema distribuido.
¿Cómo funciona un sistema distribuido?
Supongamos que tienes una máquina que tiene cuatro canales de entrada/salida. La velocidad de cada canal es de 100 MB/seg y quieres procesar un terabyte de datos en él.
Una máquina tardará 45 minutos en procesar un terabyte de datos. Ahora, supongamos que un terabyte de datos es procesado por 100 máquinas con la misma configuración.
Tardará sólo 45 segundos para que 100 máquinas procesen un terabyte de datos. Los sistemas distribuidos tardan menos tiempo en procesar Big Data.
Ahora, veamos los retos de un sistema distribuido.
Desafíos de los sistemas distribuidos
Dado que en un sistema distribuido se utilizan múltiples ordenadores, hay grandes posibilidades de que el sistema falle. También hay un límite en el ancho de banda.
La complejidad de la programación también es alta porque es difícil sincronizar los datos y el proceso. Hadoop puede hacer frente a estos desafíos.
Entendamos qué es Hadoop en la siguiente sección.
¿Qué es Hadoop?
Hadoop es un marco de trabajo que permite el procesamiento distribuido de grandes conjuntos de datos a través de clusters de ordenadores utilizando modelos de programación simples. Se inspira en un documento técnico publicado por Google.
La palabra Hadoop no tiene ningún significado. Doug Cutting, que descubrió Hadoop, le puso el nombre de su hijo elefante de juguete de color amarillo.
Discutiremos cómo Hadoop resuelve los tres retos del sistema distribuido, como son las altas probabilidades de fallo del sistema, el límite del ancho de banda y la complejidad de la programación.
Las cuatro características clave de Hadoop son:
-
Económico: Sus sistemas son muy económicos ya que se pueden utilizar ordenadores normales para el procesamiento de datos.
-
Fiable: Es fiable ya que almacena copias de los datos en diferentes máquinas y es resistente a los fallos de hardware.
-
Escalable: Es fácilmente escalable tanto horizontal como verticalmente. Unos pocos nodos adicionales ayudan a escalar el marco.
-
Flexible: Es flexible y se pueden almacenar tantos datos estructurados y no estructurados como sea necesario y decidir utilizarlos más tarde.
Tradicionalmente, los datos se almacenaban en una ubicación central, y se enviaban al procesador en tiempo de ejecución. Este método funcionaba bien para datos limitados.
Sin embargo, los sistemas modernos reciben terabytes de datos al día, y es difícil para los ordenadores tradicionales o el sistema de gestión de bases de datos relacionales (RDBMS) empujar altos volúmenes de datos al procesador.
Hadoop trajo un enfoque radical. En Hadoop, el programa va a los datos, no al revés. Inicialmente distribuye los datos a múltiples sistemas y posteriormente ejecuta el cálculo dondequiera que se encuentren los datos.
En la siguiente sección, hablaremos de cómo Hadoop se diferencia del Sistema de Base de Datos tradicional.
Diferencia entre el Sistema de Base de Datos Tradicional y Hadoop
La tabla dada a continuación le ayudará a distinguir entre el Sistema de Base de Datos Tradicional y Hadoop.
|
Sistema de Base de Datos Tradicional |
Hadoop |
|
Los datos se almacenan en una ubicación central y se envían al procesador en tiempo de ejecución. |
En Hadoop, el programa va a los datos. Inicialmente distribuye los datos a múltiples sistemas y posteriormente ejecuta el cálculo dondequiera que se encuentren los datos. |
|
Los sistemas de bases de datos tradicionales no pueden utilizarse para procesar y almacenar una cantidad significativa de datos (big data). |
Hadoop funciona mejor cuando el tamaño de los datos es grande. Puede procesar y almacenar una gran cantidad de datos de manera eficiente y eficaz. |
|
El RDBMS tradicional se utiliza para gestionar sólo datos estructurados y semiestructurados. No puede utilizarse para controlar datos no estructurados. |
Hadoop puede procesar y almacenar una gran variedad de datos, ya sean estructurados o no estructurados. |
Discutiremos la diferencia entre RDBMS tradicional y Hadoop con la ayuda de una analogía.
Habrás notado la diferencia en el estilo de alimentación de un ser humano y un tigre. Un ser humano come la comida con la ayuda de una cuchara, donde la comida se lleva a la boca. Mientras que un tigre lleva su boca hacia la comida.
Ahora, si la comida son los datos y la boca es un programa, el estilo de comer de un humano representa el RDBMS tradicional y el del tigre representa Hadoop.
Veamos el Ecosistema Hadoop en la siguiente sección.
Ecosistema Hadoop
El Ecosistema Hadoop tiene un ecosistema que ha evolucionado a partir de sus tres componentes principales: procesamiento, gestión de recursos y almacenamiento. En este tema, aprenderá los componentes del ecosistema Hadoop y cómo desempeñan sus funciones durante el procesamiento de Big Data. El ecosistema
Hadoop está creciendo continuamente para satisfacer las necesidades de Big Data. Está formado por los siguientes doce componentes:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Entenderemos el papel de cada componente del ecosistema Hadoop en las siguientes secciones.

Entendamos el papel de cada componente del ecosistema Hadoop.
Componentes del ecosistema Hadoop
Comencemos con el primer componente HDFS del ecosistema Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS es una capa de almacenamiento para Hadoop.
-
HDFS es adecuado para el almacenamiento y procesamiento distribuido, es decir, mientras se almacenan los datos, primero se distribuyen y luego se procesan.
-
HDFS proporciona acceso Streaming a los datos del sistema de archivos.
-
HDFS proporciona permiso y autenticación de archivos.
-
HDFS utiliza una interfaz de línea de comandos para interactuar con Hadoop.
¿Y qué almacena los datos en HDFS? Es el HBase que almacena los datos en HDFS.
HBase
-
HBase es una base de datos NoSQL o base de datos no relacional.
-
HBase es importante y se utiliza principalmente cuando se necesita acceso aleatorio, en tiempo real, de lectura o escritura a sus Big Data.
-
Proporciona soporte a un gran volumen de datos y un alto rendimiento.
-
En una HBase, una tabla puede tener miles de columnas.
Hemos hablado de cómo se distribuyen y almacenan los datos. Ahora, vamos a entender cómo estos datos son ingeridos o transferidos a HDFS. Sqoop hace exactamente esto.
¿Qué es Sqoop?
-
Sqoop es una herramienta diseñada para transferir datos entre Hadoop y servidores de bases de datos relacionales.
-
Se utiliza para importar datos de bases de datos relacionales (como Oracle y MySQL) a HDFS y exportar datos de HDFS a bases de datos relacionales.
Si quieres ingerir datos de eventos como datos de streaming, datos de sensores o archivos de registro, entonces puedes utilizar Flume. Veremos Flume en la siguiente sección.
Flume
-
Flume es un servicio distribuido que recoge datos de eventos y los transfiere al HDFS.
-
Es ideal para datos de eventos de múltiples sistemas.
Después de que los datos se transfieren al HDFS, se procesan. Uno de los marcos que procesan los datos es Spark.
¿Qué es Spark?
-
Spark es un marco de computación en clúster de código abierto.
-
Proporciona un rendimiento hasta 100 veces más rápido para unas pocas aplicaciones con primitivas en memoria en comparación con el paradigma MapReduce basado en disco de dos etapas de Hadoop.
-
Spark puede ejecutarse en el clúster Hadoop y procesar datos en HDFS.
-
También soporta una amplia variedad de cargas de trabajo, que incluyen Machine learning, Business intelligence, Streaming y Batch processing.
Spark tiene los siguientes componentes principales:
-
Spark Core y Resilient Distributed datasets o RDD
-
Spark SQL
-
Spark streaming
-
Librería de aprendizaje automático o Mlib
-
Graphx.
Spark es ahora ampliamente utilizado, y aprenderás más sobre él en lecciones posteriores.
Hadoop MapReduce
-
Hadoop MapReduce es el otro framework que procesa datos.
-
Es el motor de procesamiento original de Hadoop, que se basa principalmente en Java.
-
Se basa en el modelo de programación map and reduces.
-
Muchas herramientas como Hive y Pig están construidas sobre un modelo de mapa-reducción.
-
Tiene una extensa y madura tolerancia a fallos incorporada en el framework.
-
Sigue siendo muy utilizado pero pierde terreno frente a Spark.
Después de procesar los datos, se analizan. Se puede hacer mediante un sistema de flujo de datos de alto nivel de código abierto llamado Pig. Se utiliza principalmente para la analítica.
Entendamos ahora cómo se utiliza Pig para la analítica.
Pig
-
Pig convierte sus scripts en código Map y Reduce, ahorrando así al usuario la escritura de complejos programas MapReduce.
-
Las consultas ad-hoc como Filter y Join, que son difíciles de realizar en MapReduce, se pueden hacer fácilmente con Pig.
-
También se puede utilizar Impala para analizar datos.
-
Es un motor SQL de alto rendimiento de código abierto, que se ejecuta en el clúster Hadoop.
-
Es ideal para el análisis interactivo y tiene una latencia muy baja que se puede medir en milisegundos.
Impala
-
Impala soporta un dialecto de SQL, por lo que los datos en HDFS se modelan como una tabla de base de datos.
-
También puede realizar análisis de datos utilizando HIVE. Es una capa de abstracción sobre Hadoop.
-
Es muy similar a Impala. Sin embargo, se prefiere para el procesamiento de datos y las operaciones de Extract Transform Load, también conocidas como ETL.
-
Impala se prefiere para las consultas ad-hoc.
HIVE
-
HIVE ejecuta consultas utilizando MapReduce; sin embargo, un usuario no necesita escribir ningún código en MapReduce de bajo nivel.
-
Hive es adecuado para datos estructurados. Una vez analizados los datos, están listos para que los usuarios accedan a ellos.
Ahora que sabemos lo que hace HIVE, hablaremos de lo que soporta la búsqueda de datos. La búsqueda de datos se realiza mediante Cloudera Search.
Cloudera Search
-
Search es uno de los productos de acceso casi en tiempo real de Cloudera. Permite a los usuarios no técnicos buscar y explorar los datos almacenados o ingeridos en Hadoop y HBase.
-
Los usuarios no necesitan conocimientos de SQL o de programación para utilizar Cloudera Search porque proporciona una interfaz sencilla de texto completo para realizar búsquedas.
-
Otra ventaja de Cloudera Search en comparación con las soluciones de búsqueda independientes es la plataforma de procesamiento de datos totalmente integrada.
-
Cloudera Search utiliza el sistema de almacenamiento flexible, escalable y robusto que se incluye con CDH o Cloudera Distribution, incluyendo Hadoop. Esto elimina la necesidad de mover grandes conjuntos de datos a través de las infraestructuras para abordar las tareas empresariales.
-
Los trabajos de Hadoop como MapReduce, Pig, Hive y Sqoop tienen flujos de trabajo.
Oozie
-
Oozie es un flujo de trabajo o sistema de coordinación que se puede utilizar para gestionar los trabajos de Hadoop.
El ciclo de vida de la aplicación Oozie se muestra en el siguiente diagrama.
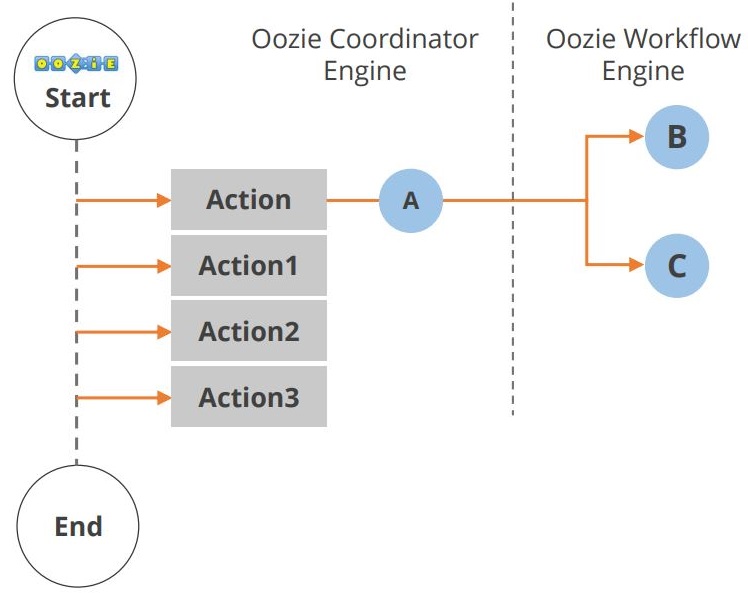 Como se puede ver, se producen múltiples acciones entre el inicio y el final del flujo de trabajo. Otro componente del ecosistema Hadoop es Hue. Veamos ahora el Hue.
Como se puede ver, se producen múltiples acciones entre el inicio y el final del flujo de trabajo. Otro componente del ecosistema Hadoop es Hue. Veamos ahora el Hue.
Hue
Hue es un acrónimo de Hadoop User Experience. Es una interfaz web de código abierto para Hadoop. Puedes realizar las siguientes operaciones utilizando Hue:
-
Cargar y navegar por los datos
-
Consultar una tabla en HIVE e Impala
-
Ejecutar trabajos y flujos de trabajo de Spark y Pig Buscar datos
-
En definitiva, Hue hace que Hadoop sea más fácil de usar.
-
También proporciona un editor SQL para HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL y Solr SQL.
Después de este breve repaso a los doce componentes del ecosistema Hadoop, ahora hablaremos de cómo estos componentes trabajan juntos para procesar Big Data.
Etapas del procesamiento de Big Data
Hay cuatro etapas de procesamiento de Big Data: Ingesta, Procesamiento, Análisis y Acceso. Veámoslas en detalle.
Ingesta
La primera etapa del procesamiento de Big Data es la Ingesta. Los datos son ingeridos o transferidos a Hadoop desde diversas fuentes como bases de datos relacionales, sistemas o archivos locales. Sqoop transfiere los datos de RDBMS a HDFS, mientras que Flume transfiere los datos de eventos.
Procesamiento
La segunda etapa es el Procesamiento. En esta etapa se almacenan y procesan los datos. Los datos se almacenan en el sistema de archivos distribuidos, HDFS, y en los datos distribuidos NoSQL, HBase. Spark y MapReduce realizan el procesamiento de los datos.
Analizar
La tercera etapa es Analizar. Aquí, los datos son analizados por marcos de procesamiento como Pig, Hive e Impala.
Pig convierte los datos utilizando un mapa y reduce y luego los analiza. Hive también se basa en la programación map and reduce y es el más adecuado para los datos estructurados.
Access
La cuarta etapa es Access, que se realiza mediante herramientas como Hue y Cloudera Search. En esta etapa, los usuarios pueden acceder a los datos analizados.
Hue es la interfaz web, mientras que Cloudera Search proporciona una interfaz de texto para explorar los datos.
¡Consulta el curso de certificación de Big Data Hadoop y Spark Developer Here!
Resumen
Resumamos ahora lo que hemos aprendido en esta lección.
-
Hadoop es un marco de trabajo para el almacenamiento y procesamiento distribuido.
-
Los componentes principales de Hadoop incluyen HDFS para el almacenamiento, YARN para la gestión de los recursos del clúster y MapReduce o Spark para el procesamiento.
-
El ecosistema Hadoop incluye múltiples componentes que soportan cada etapa del procesamiento de Big Data.
-
Flume y Sqoop ingieren los datos, HDFS y HBase almacenan los datos, Spark y MapReduce procesan los datos, Pig, Hive e Impala analizan los datos, Hue y Cloudera Search ayudan a explorar los datos.
-
Oozie gestiona el flujo de trabajo de los trabajos Hadoop.
Conclusión
Con esto concluye la lección sobre Big Data y el ecosistema Hadoop. En la próxima lección hablaremos de HDFS y YARN.
Encuentra nuestras clases de formación de Big Data Hadoop y Spark Developer Online Classroom en las principales ciudades:
| Nombre | Fecha | Lugar | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3 Abr -15 May 2021, Fin de semana lote | Su ciudad | Ver detalles |
| Big Data Hadoop and Spark Developer | 12 Abr -4 May 2021, Entre semana lote | Su ciudad | Ver detalles |
| Big Data Hadoop and Spark Developer | 24 abr -5 jun 2021, Lote de fin de semana | Su ciudad | Ver detalles |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Para aprender más, toma el Curso
Big Data Hadoop and Spark Developer Certification Training
Ir al Curso
Para aprender más, tome el Curso
Big Data Hadoop and Spark Developer Certification Training Ir al Curso