Tiempo real vs Procesamiento por lotes vs Procesamiento por flujos
Con el ritmo constante de innovación, los desarrolladores pueden esperar analizar terabytes e incluso petabytes de datos en cualquier periodo de tiempo. (Los datos, después de todo, atraen más datos.)
Esto permite numerosas ventajas, por supuesto. Pero, ¿qué hacer con todos estos datos? Puede ser difícil saber cuál es la mejor manera de acelerar y agilizar estas tecnologías, especialmente cuando las reacciones deben producirse con rapidez.
Para las empresas con vocación digital, una cuestión cada vez más importante es cómo utilizar mejor el procesamiento en tiempo real, el procesamiento por lotes y el procesamiento en flujo. Este post explicará las diferencias básicas entre estos tipos de procesamiento de datos.
Sistemas operativos en tiempo real
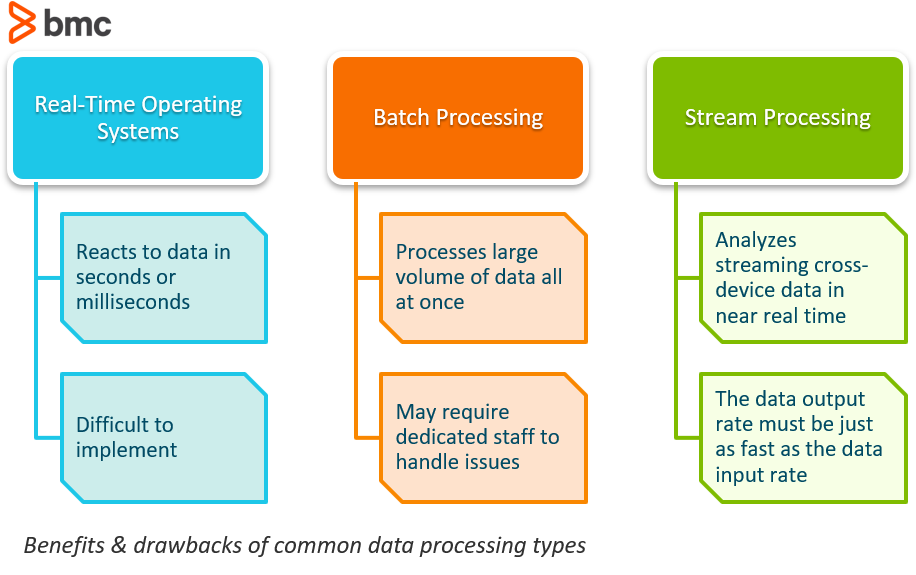
Los sistemas operativos en tiempo real suelen referirse a las reacciones a los datos. Un sistema puede clasificarse como de tiempo real si puede garantizar que la reacción se producirá dentro de un plazo ajustado del mundo real, normalmente en cuestión de segundos o milisegundos.
Uno de los mejores ejemplos de un sistema de tiempo real son los utilizados en el mercado de valores. Si una cotización de acciones debe venir de la red dentro de los 10 milisegundos de ser colocada, esto se consideraría un proceso en tiempo real. El hecho de que esto se lograra utilizando una arquitectura de software que utilizara el procesamiento en flujo o simplemente el procesamiento en hardware es irrelevante; la garantía del plazo ajustado es lo que lo convierte en tiempo real.
Otras situaciones en las que el uso de sistemas en tiempo real sería beneficioso son:
- ATMs
- Control de tráfico aéreo
- Sistemas de frenado antibloqueo en su coche
Desafíos
Aunque este tipo de sistema suena como un cambio de juego, la realidad es que los sistemas en tiempo real son extremadamente difíciles de implementar mediante el uso de sistemas de software comunes. Como estos sistemas toman el control de la ejecución del programa, aporta un nivel de abstracción totalmente nuevo.
Lo que esto significa es que la distinción entre el flujo de control de su programa y el código fuente ya no es aparente porque el sistema de tiempo real elige qué tarea ejecutar en ese momento. Esto es beneficioso, ya que permite una mayor productividad utilizando una mayor abstracción y puede facilitar el diseño de sistemas complejos, pero significa menos control en general, lo que puede ser difícil de depurar y validar.
Otro desafío común con los sistemas operativos en tiempo real es que las tareas no son entidades aisladas. El sistema decide cuáles programar y envía las tareas de mayor prioridad antes que las de menor prioridad, retrasando así su ejecución hasta que se completen todas las tareas de mayor prioridad.
Cada vez más, algunos sistemas de software están empezando a apostar por un tipo de procesamiento en tiempo real en el que el plazo no es tan absoluto como una probabilidad. Conocidos como sistemas de tiempo real suave, son capaces de cumplir normalmente o en general su plazo, aunque el rendimiento comenzará a degradarse si se pierden demasiados plazos.
Procesamiento por lotes
El procesamiento por lotes es el procesamiento de un gran volumen de datos de una sola vez. Los datos consisten fácilmente en millones de registros para un día y pueden ser almacenados en una variedad de formas (archivo, registro, etc). Los trabajos suelen completarse simultáneamente en orden secuencial y sin parar.
Un buen ejemplo de trabajo de procesamiento por lotes son todas las transacciones que una empresa financiera puede presentar en el transcurso de una semana. El procesamiento por lotes también puede utilizarse en:
- Procesos de nómina
- Facturas de partidas
- Cadena de suministro y cumplimiento
El procesamiento de datos por lotes es una forma extremadamente eficiente de procesar grandes cantidades de datos que se recogen durante un período de tiempo. También ayuda a reducir los costes operativos que las empresas pueden gastar en mano de obra, ya que no requiere empleados especializados en la introducción de datos para apoyar su funcionamiento. Se puede utilizar fuera de línea y da a los gerentes un control completo en cuanto a cuándo iniciar el procesamiento, ya sea durante la noche o al final de una semana o período de pago.
Desafíos
Como con cualquier cosa, hay algunas desventajas al utilizar el software de procesamiento por lotes. Uno de los mayores problemas que ven las empresas es que la depuración de estos sistemas puede ser complicada. Si no se cuenta con un equipo o profesional de TI dedicado, tratar de arreglar el sistema cuando se produce un error podría ser perjudicial, lo que provocaría la necesidad de contar con la ayuda de un consultor externo.
Otro problema del procesamiento por lotes es que las empresas suelen implementarlo para ahorrar dinero, pero el software y la formación requieren una cantidad decente de gastos al principio. Los gerentes necesitarán ser entrenados para entender:
- Cómo programar un lote
- Qué los activa
- Qué significan ciertas notificaciones
(Aprenda más sobre el procesamiento moderno de lotes.)
Procesamiento de flujos
El procesamiento de flujos es el proceso de poder analizar casi instantáneamente los datos que fluyen de un dispositivo a otro.
Este método de computación continua ocurre a medida que los datos fluyen a través del sistema sin limitaciones de tiempo obligatorias en la salida. Con el flujo casi instantáneo, los sistemas no requieren que se almacenen grandes cantidades de datos.
El procesamiento en flujo es muy beneficioso si los eventos que se desean rastrear ocurren con frecuencia y cerca en el tiempo. También es mejor utilizarlo si el evento necesita ser detectado de inmediato y respondido rápidamente. El procesamiento de flujos, por tanto, es útil para tareas como la detección de fraudes y la ciberseguridad. Si los datos de las transacciones se procesan en flujo, las transacciones fraudulentas pueden identificarse y detenerse incluso antes de que se completen.
Desafíos
Uno de los mayores desafíos a los que se enfrentan las organizaciones con el procesamiento en flujo es que la tasa de salida de datos a largo plazo del sistema debe ser igual de rápida, o más rápida, que la tasa de entrada de datos a largo plazo, de lo contrario el sistema empezará a tener problemas con el almacenamiento y la memoria.
Otro desafío es tratar de averiguar la mejor manera de hacer frente a la enorme cantidad de datos que se genera y se mueve. Para que el flujo de datos a través del sistema funcione al máximo nivel óptimo, es necesario que las organizaciones creen un plan sobre cómo reducir el número de copias, cómo orientar los núcleos de computación y cómo utilizar la jerarquía de la caché de la mejor manera posible.
Conclusión
Aunque todos estos sistemas tienen ventajas, al final las organizaciones deben considerar los beneficios potenciales de cada uno para decidir qué método es el más adecuado para el caso de uso.
Recursos adicionales
- Blog de automatización de la carga de trabajo de BMC
- Blog de Big Data de BMC
- Guía para principiantes sobre la automatización del lugar de trabajo
- ¿Qué es un trabajo por lotes?
- ¿Qué es una canalización de datos?
Gestione sl as para sus servicios por lotes joe goldberg de BMC Software
Adopte un enfoque moderno para el procesamiento por lotes

Estas publicaciones son propias y no representan necesariamente la posición, las estrategias o la opinión de BMC.
¿Ve un error o tiene una sugerencia? Háganoslo saber enviando un correo electrónico a [email protected].