Reddit AmItheAsshole es más amable con las mujeres que con los hombres – una prueba SQL?
Cuando los redditors preguntan «¿soy el gilipollas?» mientras hablan de las mujeres, tienen un mayor cambio de ser juzgados como el gilipollas. Comprobemos estas métricas – con BigQuery, dbt y Data Studio
Asegúrate de no tomar nada de lo que he escrito aquí como la verdad absoluta. Varias personas en Twitter señalaron problemas y añadieron correcciones al análisis que ofrecí. Leer este post tal y como se presentó originalmente – y las reacciones – puede ser una gran manera de aprender tanto como lo hice yo al leer las respuestas. Puedes encontrar muchos de sus pensamientos no filtrados siguiendo este hilo de Twitter.
Contexto
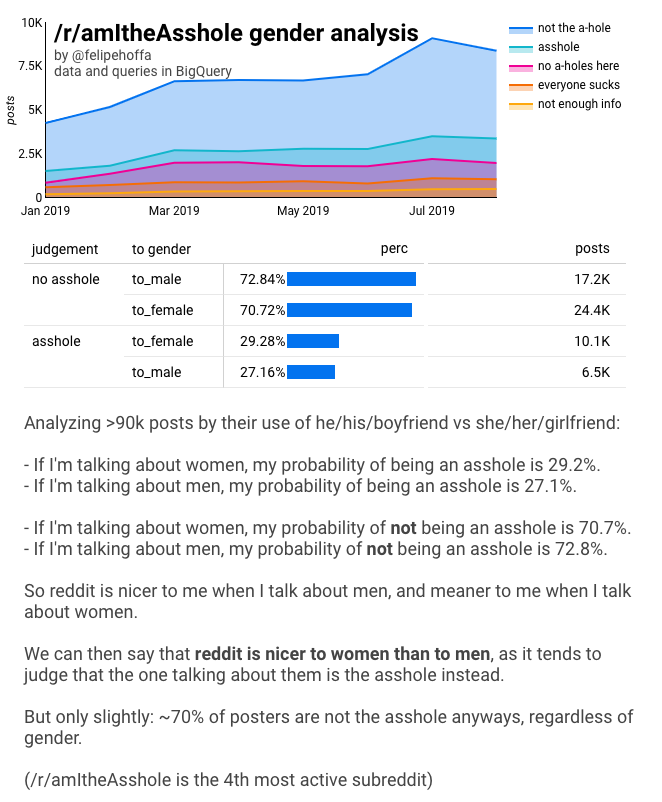
/r/amItheAsshole ha crecido hasta convertirse en el cuarto subreddit más activo – por número de comentarios. La gente viene a este subreddit a contar sus historias, y preguntan a otros redditors «¿soy el gilipollas aquí?». Resulta que la mayoría de la gente es juzgada como «no es el gilipollas», como se ve en este gráfico:
Mi tuit con estos resultados obtuvo mucha atención:
Incluyendo la pregunta – ¿es reddit más amable con las mujeres o con los hombres?
Decidir el género
Mirando el título o el contenido de un post, puede que te cueste decidir si el «yo» es un hombre o una mujer – pero es bastante fácil contar el número de «ella/él/su/novia/novio» presentes en la historia.
Veamos algunos posts al azar, y el recuento de cada uno de estos pronombres y palabras de género:
Podemos ver que el recuento de pronombres y palabras de género en el ejemplo coincide con el tema de la historia. Estas historias son sobre un cliente masculino, una novia femenina, un vecino masculino, un hijo masculino y una hija adolescente femenina.
Con estos números, ahora podemos establecer una regla arbitraria: si hay más del doble de pronombres masculinos que femeninos, ese post es sobre un hombre. Si hay más del doble de pronombres masculinos que femeninos, la entrada se refiere a un hombre. Si los números están muy cerca o son nulos, llamaremos al post «neutro».
Otra regla que podemos establecer para simplificar el análisis:
- Si el juicio es «no es el gilipollas» o «aquí no hay gilipollas» entonces podemos decir «el cartel no es un gilipollas».
- Si el juicio es ‘gilipollas’ o ‘todos dan asco’ entonces podemos decir ‘el cartel es un gilipollas’.
Si agregamos todos estos posts, llegamos a los números:

Cuando presenté por primera vez estos resultados, me dijeron «estos números están demasiado cerca, podrían ser un error estadístico».
¿Significación estadística?
¿Cómo podemos saber que los números no son un mero error estadístico? Veamos la tendencia mes a mes: ¿es estable?

¡Sí! La tendencia varía mes a mes, pero hay una clara mayor probabilidad de ser gilipollas cuando se habla de mujeres que cuando se habla de hombres. Si la pequeña diferencia fuera sólo una casualidad estadística, esperaríamos que la tendencia saltara salvajemente en su lugar.
Y ten en cuenta que estos resultados son muy específicos, como señala este tuit:
A lo que respondí
Cómo
Esta vez estoy usando dbt por primera vez, y dejé todo mi código en GitHub. ¡Gracias Claire Carroll por tu ayuda para empezar con esta impresionante herramienta!
Para extraer todos los posts de /r/AmItheAsshole en BigQuery a una nueva tabla, se puede hacer:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Después se puede determinar el género y la sentencia de cada post con una consulta como:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
Y finalmente las estadísticas presentadas aquí:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Discusión
Encontrarás un montón de respuestas perspicaces y entretenidas en el hilo de twitter de este post:
No dudes en unirte a la discusión (¿y decirme si me equivoco?). Recuerde que debe ser amable con los demás – la mayoría de la gente no es el culo de todos modos.
¿Quieres más?
Sólo cubrí hasta agosto de 2019, ya que es cuando el actual archivo completo de reddit en BigQuery se detiene – hasta futuras actualizaciones previstas. Revisa mi post anterior para más detalles sobre la recolección de datos en vivo de pushshift.io. Gracias Jason Baumgartner por el suministro constante!
Soy Felipe Hoffa, un Developer Advocate para Google Cloud. Sígueme en @felipehoffa, encuentra mis posts anteriores en medium.com/@hoffa, y todo sobre BigQuery en reddit.com/r/bigquery.