Echtzeit vs. Batch-Verarbeitung vs. Stream-Verarbeitung
Mit dem konstanten Innovationstempo können Entwickler damit rechnen, in einem bestimmten Zeitraum Terabytes und sogar Petabytes an Daten zu analysieren. (Daten ziehen schließlich immer mehr Daten an.)
Dies bietet natürlich zahlreiche Vorteile. Aber was soll man mit all diesen Daten machen? Es kann schwierig sein, den besten Weg zu finden, um diese Technologien zu beschleunigen und zu beschleunigen, vor allem, wenn Reaktionen schnell erfolgen müssen.
Für Digital-First-Unternehmen stellt sich zunehmend die Frage, wie man Echtzeitverarbeitung, Stapelverarbeitung und Stream Processing am besten einsetzt. In diesem Beitrag werden die grundlegenden Unterschiede zwischen diesen Datenverarbeitungstypen erläutert.
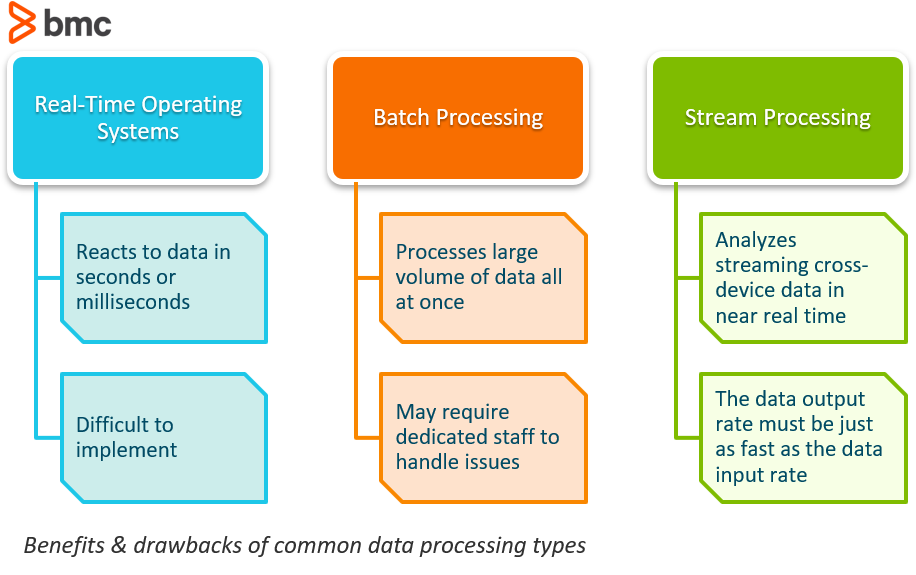
Echtzeitbetriebssysteme
Echtzeitbetriebssysteme beziehen sich in der Regel auf die Reaktionen auf Daten. Ein System kann als echtzeitfähig eingestuft werden, wenn es garantieren kann, dass die Reaktion innerhalb eines engen Zeitrahmens erfolgt, in der Regel innerhalb von Sekunden oder Millisekunden.
Eines der besten Beispiele für ein Echtzeitsystem sind die an der Börse verwendeten Systeme. Wenn ein Börsenkurs innerhalb von 10 Millisekunden nach seiner Eingabe aus dem Netz kommt, würde man dies als Echtzeitprozess bezeichnen. Ob dies durch eine Software-Architektur mit Stream-Processing oder nur durch die Verarbeitung in der Hardware erreicht wurde, ist irrelevant; die Garantie der knappen Frist ist das, was es zu Echtzeit macht.
Andere Situationen, in denen der Einsatz von Echtzeitsystemen von Vorteil wäre, sind:
- ATMs
- Luftverkehrskontrolle
- Antiblockiersysteme in Ihrem Auto
Herausforderungen
Während diese Art von System wie ein Game Changer klingt, ist die Realität, dass Echtzeitsysteme extrem schwer durch die Verwendung von üblichen Softwaresystemen zu implementieren sind. Da diese Systeme die Kontrolle über die Programmausführung übernehmen, ergibt sich eine völlig neue Abstraktionsebene.
Das bedeutet, dass der Unterschied zwischen dem Kontrollfluss Ihres Programms und dem Quellcode nicht mehr offensichtlich ist, da das Echtzeitsystem entscheidet, welche Aufgabe zu diesem Zeitpunkt ausgeführt wird. Dies ist vorteilhaft, da es eine höhere Produktivität durch höhere Abstraktion ermöglicht und den Entwurf komplexer Systeme erleichtern kann, aber es bedeutet insgesamt weniger Kontrolle, was schwierig zu debuggen und zu validieren sein kann.
Eine weitere häufige Herausforderung bei Echtzeitbetriebssystemen ist, dass die Tasks keine isolierten Einheiten sind. Das System entscheidet, welche Aufgaben geplant werden sollen, und schickt Aufgaben mit höherer Priorität vor denen mit niedrigerer Priorität los, wodurch sich deren Ausführung verzögert, bis alle Aufgaben mit höherer Priorität abgeschlossen sind.
Immer mehr beginnen einige Softwaresysteme, sich für eine Variante der Echtzeitverarbeitung zu entscheiden, bei der die Frist keine absolute Größe ist, sondern eine Wahrscheinlichkeit. Diese als weiche Echtzeitsysteme bezeichneten Systeme sind in der Regel in der Lage, ihre Fristen einzuhalten, obwohl die Leistung nachlässt, wenn zu viele Fristen verpasst werden.
Stapelverarbeitung
Stapelverarbeitung ist die Verarbeitung einer großen Datenmenge auf einmal. Die Daten bestehen leicht aus Millionen von Datensätzen für einen Tag und können auf verschiedene Weise gespeichert werden (Datei, Datensatz usw.). Die Aufträge werden in der Regel gleichzeitig und ohne Unterbrechung in sequentieller Reihenfolge ausgeführt.
Ein typisches Beispiel für einen Stapelverarbeitungsauftrag sind alle Transaktionen, die ein Finanzunternehmen im Laufe einer Woche einreichen könnte. Die Stapelverarbeitung kann auch in folgenden Bereichen eingesetzt werden:
- Gehaltsabrechnungen
- Rechnungen für Einzelposten
- Lieferkette und Auftragsabwicklung
Die Stapelverarbeitung ist eine äußerst effiziente Methode zur Verarbeitung großer Datenmengen, die über einen bestimmten Zeitraum gesammelt werden. Sie trägt auch dazu bei, die Betriebskosten zu senken, die Unternehmen für Personal ausgeben könnten, da sie keine spezialisierten Dateneingabebeamten zur Unterstützung ihrer Funktion benötigt. Sie kann offline verwendet werden und gibt Managern die vollständige Kontrolle darüber, wann die Verarbeitung beginnen soll, sei es über Nacht oder am Ende einer Woche oder eines Zahlungszeitraums.
Herausforderungen
Wie bei allem gibt es auch bei der Verwendung von Stapelverarbeitungssoftware ein paar Nachteile. Eines der größten Probleme für Unternehmen ist, dass die Fehlersuche in diesen Systemen schwierig sein kann. Wenn Sie nicht über ein spezielles IT-Team oder einen Fachmann verfügen, kann der Versuch, das System zu reparieren, wenn ein Fehler auftritt, nachteilig sein, so dass ein externer Berater hinzugezogen werden muss.
Ein weiteres Problem bei der Stapelverarbeitung besteht darin, dass Unternehmen sie in der Regel einführen, um Geld zu sparen, aber die Software und die Schulung erfordern anfangs eine beträchtliche Summe an Ausgaben. Manager müssen geschult werden, um zu verstehen:
- Wie man einen Stapel plant
- Was sie auslöst
- Was bestimmte Benachrichtigungen bedeuten
(Erfahren Sie mehr über moderne Stapelverarbeitung.)
Stream Processing
Stream Processing ist ein Prozess, bei dem Daten, die von einem Gerät zu einem anderen fließen, fast sofort analysiert werden können.
Diese Methode der kontinuierlichen Berechnung geschieht, während die Daten durch das System fließen, ohne dass die Ausgabe zeitlich begrenzt ist. Durch den fast sofortigen Fluss benötigen die Systeme keine großen Datenmengen, die gespeichert werden müssen.
Die Datenstromverarbeitung ist sehr vorteilhaft, wenn die Ereignisse, die Sie verfolgen möchten, häufig und zeitlich eng beieinander liegen. Sie ist auch dann am besten geeignet, wenn das Ereignis sofort erkannt werden muss und schnell reagiert werden soll. Stream-Processing ist also nützlich für Aufgaben wie Betrugserkennung und Cybersicherheit. Wenn Transaktionsdaten als Datenstrom verarbeitet werden, können betrügerische Transaktionen erkannt und gestoppt werden, bevor sie überhaupt abgeschlossen sind.
Herausforderungen
Eine der größten Herausforderungen für Unternehmen bei der Datenstromverarbeitung besteht darin, dass die langfristige Datenausgaberate des Systems genauso schnell oder schneller sein muss als die langfristige Dateneingaberate, da das System sonst Probleme mit der Speicherung und dem Speicher bekommt.
Eine weitere Herausforderung besteht darin, herauszufinden, wie man am besten mit den riesigen Datenmengen umgeht, die erzeugt und bewegt werden. Um den Datenfluss durch das System auf höchstem Niveau zu halten, müssen Unternehmen einen Plan erstellen, wie sie die Anzahl der Kopien reduzieren, die Rechenkerne gezielt einsetzen und die Cache-Hierarchie bestmöglich nutzen können.
Fazit
Auch wenn alle diese Systeme Vorteile haben, sollten Unternehmen letztendlich die potenziellen Vorteile jedes einzelnen abwägen, um zu entscheiden, welche Methode für den jeweiligen Anwendungsfall am besten geeignet ist.
Zusätzliche Ressourcen
- BMC Workload Automation Blog
- BMC Big Data Blog
- Anfängerleitfaden zur Workplace Automation
- Was ist ein Batch-Job?
- Was ist eine Datenpipeline?
Manage sl as für Ihre Batch-Services joe goldberg von BMC Software
Take a modern approach to batch processing

Diese Beiträge sind meine eigenen und repräsentieren nicht notwendigerweise die Position, Strategien oder Meinungen von BMC.
Sie sehen einen Fehler oder haben einen Vorschlag? Bitte lassen Sie es uns wissen, indem Sie uns eine E-Mail an [email protected] schicken.