Tutorial om Big Data og Hadoop-økosystemet
Velkommen til den første lektion ‘Big Data og Hadoop-økosystemet’ i Big Data Hadoop tutorial, som er en del af ‘Big Data Hadoop and Spark Developer Certification course’, der tilbydes af Simplilearn. Denne lektion er en introduktion til Big Data og Hadoop-økosystemet. I det næste afsnit vil vi diskutere målene for denne lektion.
Målsætninger
Når du har gennemført denne lektion, vil du være i stand til at:
-
Forstå begrebet Big Data og dets udfordringer
-
Forklare, hvad Big Data er
-
Forklare, hvad Hadoop er
-
Forklare, hvad Hadoop er og hvordan det løser Big Data-udfordringer
-
Beskriv Hadoop-økosystemet
Lad os nu tage et kig på oversigt over Big Data og Hadoop.
Overblik over Big Data og Hadoop
For år 2000 var data relativt små, end de er i dag; databehandling var dog kompleks. Al databeregning var afhængig af de tilgængelige computeres processorkraft.
Spå et senere tidspunkt, da data voksede, var løsningen at have computere med stor hukommelse og hurtige processorer. Men efter 2000 blev dataene ved med at vokse, og den oprindelige løsning kunne ikke længere hjælpe.
I løbet af de sidste par år har der været en utrolig eksplosion i mængden af data. IBM rapporterede, at der blev genereret 2,5 exabyte, eller 2,5 milliarder gigabyte, data hver dag i 2012.
Her er nogle statistikker, der angiver udbredelsen af data fra Forbes, september 2015. Der udføres 40.000 søgeforespørgsler på Google hvert sekund. Der uploades op til 300 timers video til YouTube hvert minut.
I Facebook sendes der 31,25 millioner beskeder af brugerne, og der ses 2,77 millioner videoer hvert minut. I 2017 vil næsten 80 % af alle fotos blive taget på smartphones.
I 2020 vil mindst en tredjedel af alle data passere gennem skyen (et netværk af servere, der er forbundet via internettet). I 2020 vil der hvert sekund blive skabt ca. 1,7 megabyte nye oplysninger for hvert menneske på planeten.
Data vokser hurtigere end nogensinde før. Man kan bruge flere computere til at håndtere disse stadigt voksende data. I stedet for at én maskine udfører opgaven, kan du bruge flere maskiner. Dette kaldes et distribueret system.
Du kan tjekke Big Data Hadoop and Spark Developer Certification Course Preview her!
Lad os se på et eksempel for at forstå, hvordan et distribueret system fungerer.
Hvordan fungerer et distribueret system?
Sæt, du har én maskine, som har fire input/output-kanaler. Hastigheden for hver kanal er 100 MB/sek., og du ønsker at behandle en terabyte data på den.
Det vil tage 45 minutter for en maskine at behandle en terabyte data. Lad os nu antage, at en terabyte data behandles af 100 maskiner med den samme konfiguration.
Det vil kun tage 45 sekunder for 100 maskiner at behandle en terabyte data. Distribuerede systemer tager mindre tid at behandle Big Data.
Lad os nu se på udfordringerne ved et distribueret system.
Udfordringer ved distribuerede systemer
Da der anvendes flere computere i et distribueret system, er der store chancer for systemfejl. Der er også en begrænsning på båndbredden.
Programmeringskompleksiteten er også høj, fordi det er svært at synkronisere data og proces. Hadoop kan tackle disse udfordringer.
Lad os forstå, hvad Hadoop er i det næste afsnit.
Had er Hadoop?
Hadoop er en ramme, der gør det muligt at distribuere behandling af store datasæt på tværs af klynger af computere ved hjælp af enkle programmeringsmodeller. Det er inspireret af et teknisk dokument offentliggjort af Google.
Ordet Hadoop har ikke nogen betydning. Doug Cutting, der opdagede Hadoop, opkaldte det efter sin søns gulfarvede legetøjselefant.
Lad os diskutere, hvordan Hadoop løser de tre udfordringer ved det distribuerede system, såsom store chancer for systemfejl, begrænsningen af båndbredde og programmeringskompleksitet.
De fire vigtigste karakteristika ved Hadoop er:
-
Økonomisk: Dens systemer er meget økonomiske, da almindelige computere kan bruges til databehandling.
-
Pålidelige: Det er pålideligt, da det gemmer kopier af dataene på forskellige maskiner og er modstandsdygtigt over for hardwarefejl.
-
Skalerbart: Det er let skalerbart både horisontalt og vertikalt. Et par ekstra knuder hjælper med at skalere rammen op.
-
Fleksibel: Det er fleksibelt, og du kan gemme så mange strukturerede og ustrukturerede data, som du har brug for, og beslutte at bruge dem senere.
Traditionelt blev data gemt et centralt sted, og de blev sendt til processoren på køretid. Denne metode fungerede godt til begrænsede data.
Midlertid modtager moderne systemer terabytes af data om dagen, og det er svært for de traditionelle computere eller RDBMS (Relational Database Management System) at skubbe store mængder data til processoren.
Hadoop bragte en radikal tilgang. I Hadoop går programmet til dataene og ikke omvendt. Det distribuerer i første omgang dataene til flere systemer og kører senere beregningen der, hvor dataene befinder sig.
I det følgende afsnit vil vi tale om, hvordan Hadoop adskiller sig fra det traditionelle databasesystem.
Forskellen mellem traditionelt databasesystem og Hadoop
Den nedenstående tabel vil hjælpe dig med at skelne mellem traditionelt databasesystem og Hadoop.
|
Traditionelt databasesystem |
Hadoop |
|
Data gemmes centralt og sendes til processoren ved kørselstid. |
I Hadoop går programmet til dataene. Det distribuerer i første omgang dataene til flere systemer og kører senere beregningen, uanset hvor dataene befinder sig. |
|
Traditionelle databasesystemer kan ikke bruges til at behandle og lagre en betydelig mængde data(big data). |
Hadoop fungerer bedre, når datastørrelsen er stor. Det kan behandle og lagre en stor mængde data effektivt og virkningsfuldt. |
|
Traditionelle RDBMS bruges kun til at håndtere strukturerede og semistrukturerede data. Det kan ikke bruges til at styre ustrukturerede data. |
Hadoop kan behandle og lagre en række forskellige data, uanset om de er strukturerede eller ustrukturerede. |
Lad os diskutere forskellen mellem traditionelle RDBMS og Hadoop ved hjælp af en analogi.
Du har sikkert bemærket forskellen i et menneskes og en tigers spisestil. Et menneske spiser mad ved hjælp af en ske, hvor maden føres til munden. Hvorimod en tiger fører munden hen til maden.
Nu, hvis maden er data, og munden er et program, så er et menneskes spisestil et billede på traditionelt RDBMS, og tigerens stil et billede på Hadoop.
Lad os se på Hadoop-økosystemet i det næste afsnit.
Hadoop-økosystemet
Hadoop-økosystemet Hadoop har et økosystem, der har udviklet sig fra de tre kernekomponenter behandling, ressourcestyring og lagring. I dette emne lærer du om komponenterne i Hadoop-økosystemet, og hvordan de udfylder deres roller under Big Data-behandling. Det
Hadoop-økosystem vokser løbende for at opfylde behovene for Big Data. Det består af følgende tolv komponenter:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Du vil lære om den rolle, som hver enkelt komponent i Hadoop-økosystemet spiller, i de næste afsnit.

Lad os forstå den rolle, som hver enkelt komponent i Hadoop-økosystemet spiller.
Komponenter i Hadoop-økosystemet
Lad os starte med den første komponent HDFS i Hadoop-økosystemet.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS er et lag til lagring i Hadoop.
-
HDFS er velegnet til distribueret lagring og behandling, dvs. mens dataene lagres, bliver de først distribueret, og derefter behandles de.
-
HDFS giver Streaming-adgang til filsystemdata.
-
HDFS giver filtilladelse og autentificering.
-
HDFS bruger en kommandolinjeinterface til at interagere med Hadoop.
Så hvad gemmer data i HDFS? Det er HBase, som gemmer data i HDFS.
HBase
-
HBase er en NoSQL-database eller ikke-relationel database.
-
HBase er vigtig og bruges primært, når du har brug for tilfældig, realtids-, læse- eller skriveadgang til dine Big Data.
-
Den giver støtte til en stor datamængde og høj gennemstrømning.
-
I en HBase kan en tabel have tusindvis af kolonner.
Vi diskuterede, hvordan data distribueres og lagres. Lad os nu forstå, hvordan disse data indlæses eller overføres til HDFS. Sqoop gør netop dette.
Hvad er Sqoop?
-
Sqoop er et værktøj, der er designet til at overføre data mellem Hadoop og relationelle databaseservere.
-
Det bruges til at importere data fra relationelle databaser (såsom Oracle og MySQL) til HDFS og eksportere data fra HDFS til relationelle databaser.
Hvis du ønsker at indlæse hændelsesdata såsom streamingdata, sensordata eller logfiler, kan du bruge Flume. Vi vil se på Flume i næste afsnit.
Flume
-
Flume er en distribueret tjeneste, der indsamler hændelsesdata og overfører dem til HDFS.
-
Det er ideelt egnet til hændelsesdata fra flere systemer.
Når dataene er overført til HDFS, behandles de. Et af de frameworks, der behandler data, er Spark.
Hvad er Spark?
-
Spark er et open source cluster computing framework.
-
Det giver op til 100 gange hurtigere ydeevne for nogle få applikationer med in-memory-primitiver sammenlignet med det to-trins diskbaserede MapReduce-paradigme i Hadoop.
-
Spark kan køre i Hadoop-klyngen og behandle data i HDFS.
-
Det understøtter også en bred vifte af arbejdsbyrder, som omfatter maskinlæring, business intelligence, streaming og batchbehandling.
Spark er et open source cluster computing framework.
Det giver op til 100 gange hurtigere ydeevne for nogle få applikationer med in-memory-primitiver sammenlignet med det to-trins diskbaserede MapReduce-paradigme i Hadoop.
Spark kan køre i Hadoop-klyngen og behandle data i HDFS.
Det understøtter også en bred vifte af arbejdsbyrder, som omfatter maskinlæring, business intelligence, streaming og batchbehandling.
Spark har følgende hovedkomponenter:
-
Spark Core og Resilient Distributed datasets eller RDD
-
Spark SQL
-
Spark streaming
-
Spark streaming
-
Machine learning library eller Mlib
-
Graphx.
Spark er nu meget udbredt, og du vil lære mere om det i de efterfølgende lektioner.
Hadoop MapReduce
-
Hadoop MapReduce er den anden ramme, der behandler data.
-
Det er den oprindelige Hadoop-behandlingsmotor, som primært er Java-baseret.
-
Det er baseret på programmeringsmodellen map and reduces.
-
Mange værktøjer som Hive og Pig er bygget på en map-reduce-model.
-
Det har en omfattende og moden fejltolerance indbygget i rammen.
-
Det er stadig meget almindeligt anvendt, men taber terræn til Spark.
Når dataene er behandlet, analyseres de. Det kan gøres ved hjælp af et open source-datastrømssystem på højt niveau kaldet Pig. Det bruges hovedsageligt til analyse.
Lad os nu forstå, hvordan Pig bruges til analyse.
Pig
-
Pig konverterer sine scripts til Map- og Reduce-kode og sparer dermed brugeren for at skrive komplekse MapReduce-programmer.
-
Ad-hoc forespørgsler som Filter og Join, som er vanskelige at udføre i MapReduce, kan nemt udføres ved hjælp af Pig.
-
Du kan også bruge Impala til at analysere data.
-
Det er en open source højtydende SQL-motor med høj ydeevne, som kører på Hadoop-klyngen.
-
Det er ideelt til interaktive analyser og har meget lav latenstid, som kan måles i millisekunder.
Impala
-
Impala understøtter en dialekt af SQL, så data i HDFS modelleres som en databasetabel.
-
Du kan også udføre dataanalyse ved hjælp af HIVE. Det er et abstraktionslag oven på Hadoop.
-
Det minder meget om Impala. Det foretrækkes dog til databehandling og Extract Transform Load, også kendt som ETL, operationer.
-
Impala foretrækkes til ad-hoc forespørgsler.
HIVE
-
HIVE udfører forespørgsler ved hjælp af MapReduce; en bruger behøver dog ikke at skrive nogen kode i MapReduce på lavt niveau.
-
Hive er velegnet til strukturerede data. Når dataene er analyseret, er de klar til, at brugerne kan få adgang til dem.
Nu da vi ved, hvad HIVE gør, vil vi diskutere, hvad der understøtter søgningen af data. Datasøgning sker ved hjælp af Cloudera Search.
Cloudera Search
-
Search er et af Clouderas produkter til nær-realtidsadgang. Det giver ikke-tekniske brugere mulighed for at søge og udforske data, der er lagret i eller indtastet i Hadoop og HBase.
-
Brugerne behøver ikke SQL- eller programmeringskompetencer for at bruge Cloudera Search, fordi det giver en simpel fuldtekstgrænseflade til søgning.
-
En anden fordel ved Cloudera Search sammenlignet med enkeltstående søgeløsninger er den fuldt integrerede databehandlingsplatform.
-
Cloudera Search bruger det fleksible, skalerbare og robuste lagringssystem, der er inkluderet i CDH eller Cloudera Distribution, herunder Hadoop. Dette eliminerer behovet for at flytte store datasæt på tværs af infrastrukturer for at løse forretningsopgaver.
-
Hadoop-jobs som MapReduce, Pig, Hive og Sqoop har arbejdsgange.
Oozie
-
Oozie er et workflow- eller koordineringssystem, som du kan bruge til at administrere Hadoop-jobs.
Oozie-applikationens livscyklus er vist i diagrammet nedenfor.
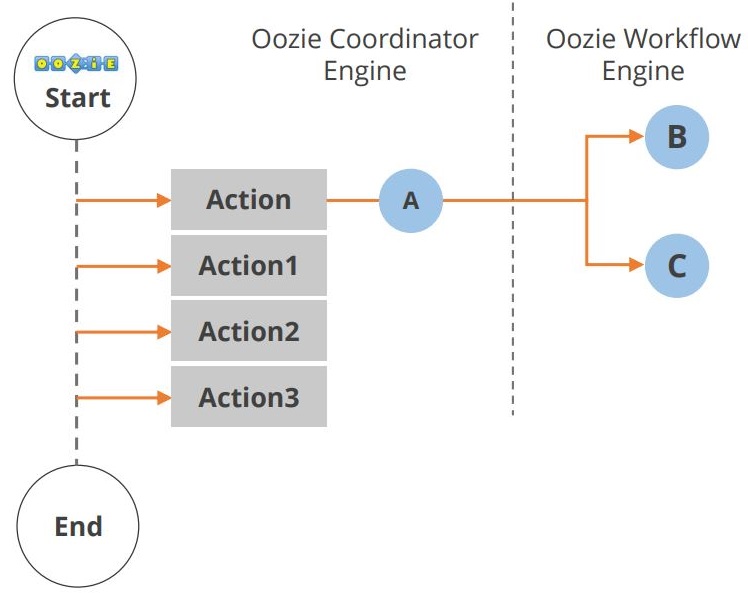 Som du kan se, sker der flere handlinger mellem starten og slutningen af workflowet. En anden komponent i Hadoop-økosystemet er Hue. Lad os nu se på Hue.
Som du kan se, sker der flere handlinger mellem starten og slutningen af workflowet. En anden komponent i Hadoop-økosystemet er Hue. Lad os nu se på Hue.
Hue
Hue er en forkortelse for Hadoop User Experience. Det er en webgrænseflade med åben kildekode til Hadoop. Du kan udføre følgende operationer ved hjælp af Hue:
-
Opload og gennemse data
-
Søgning af en tabel i HIVE og Impala
-
Kør Spark- og Pig-jobs og arbejdsgange Søg data
-
Samlet set gør Hue Hadoop nemmere at bruge.
-
Det giver også SQL-editor til HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL og Solr SQL.
Efter denne korte oversigt over de tolv komponenter i Hadoop-økosystemet vil vi nu diskutere, hvordan disse komponenter arbejder sammen om at behandle Big Data.
Trin i Big Data-behandling
Der er fire trin i Big Data-behandling: Ingest, Processing, Analyze, Access. Lad os se på dem i detaljer.
Ingest
Den første fase af Big Data-behandling er Ingest. Dataene indtages eller overføres til Hadoop fra forskellige kilder som f.eks. relationelle databaser, systemer eller lokale filer. Sqoop overfører data fra RDBMS til HDFS, mens Flume overfører hændelsesdata.
Processing
Den anden fase er Processing. I dette trin lagres og behandles dataene. Dataene gemmes i det distribuerede filsystem, HDFS, og de distribuerede NoSQL-data, HBase. Spark og MapReduce udfører databehandlingen.
Analyse
Den tredje fase er Analysere. Her analyseres dataene af behandlingsrammer som Pig, Hive og Impala.
Pig konverterer dataene ved hjælp af en map og reduce og analyserer dem derefter. Hive er også baseret på map and reduce-programmering og er mest velegnet til strukturerede data.
Access
Den fjerde fase er Access, som udføres af værktøjer som Hue og Cloudera Search. I dette trin kan brugerne få adgang til de analyserede data.
Hue er webgrænsefladen, mens Cloudera Search giver en tekstgrænseflade til at udforske data.
Tjek Big Data Hadoop and Spark Developer Certification kurset ud her!
Summary
Lad os nu opsummere, hvad vi har lært i denne lektion.
-
Hadoop er en ramme for distribueret lagring og behandling.
-
Kernekomponenterne i Hadoop omfatter HDFS til lagring, YARN til klyngeresourcehåndtering og MapReduce eller Spark til behandling.
-
Hadoop-økosystemet omfatter flere komponenter, der understøtter hvert trin af Big Data-behandlingen.
-
Flume og Sqoop indtager data, HDFS og HBase lagrer data, Spark og MapReduce behandler data, Pig, Hive og Impala analyserer data, Hue og Cloudera Search hjælper med at udforske data.
-
Oozie styrer arbejdsgangen for Hadoop-jobs.
Konklusion
Dette er afslutningen på lektionen om Big Data og Hadoop-økosystemet. I den næste lektion vil vi diskutere HDFS og YARN.
Find vores Big Data Hadoop and Spark Developer Online Classroom-uddannelsesklasser i de bedste byer:
| Navn | Dato | Sted | |
|---|---|---|---|
| Big Data Hadoop og Spark Developer | 3 apr -15 maj 2021, Weekend batch | Din by | Se detaljer |
| Big Data Hadoop and Spark Developer | 12 apr -4 maj 2021, Hverdage batch | Din by | Se detaljer |
| Big Data Hadoop and Spark Developer | 24 apr -5 jun 2021, Weekend batch | Din by | Se detaljer |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
For at lære mere, tag Kursus
Big Data Hadoop and Spark Developer Certification Training
Gå til Kursus
For at lære mere, tage kurset
Big Data Hadoop and Spark Developer Certification Training Gå til kursus