Reddit AmItheAsshole er pænere mod kvinder end mod mænd – et SQL-bevis?
Når redditors spørger “er jeg et røvhul”, mens de taler om kvinder, har de en større chance for at blive dømt som et røvhul. Lad os tjekke disse målinger – med BigQuery, dbt og Data Studio
Sørg for ikke at tage noget af det, jeg har skrevet her, som den absolutte sandhed. Flere personer på Twitter bemærkede problemer og tilføjede rettelser til den analyse, jeg tilbød. At læse dette indlæg som oprindeligt præsenteret – og reaktionerne – kan være en god måde for dig at lære lige så meget, som jeg gjorde, mens jeg læste svarene. Du kan finde mange af deres ufiltrerede tanker ved at følge denne Twitter-tråd.
Context
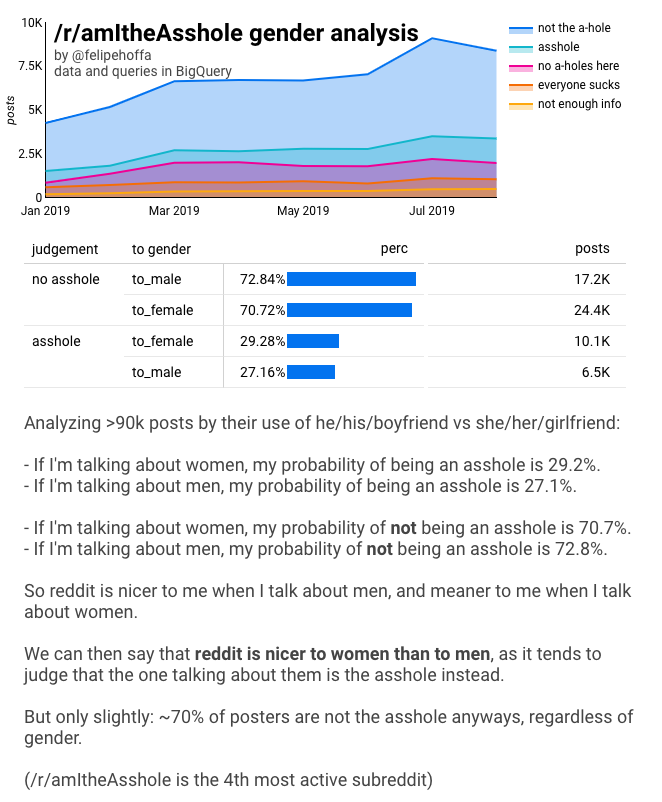
/r/amItheAsshole er vokset til at være den fjerde mest aktive subreddit – målt på antal kommentarer. Folk kommer til dette subreddit for at fortælle deres historier, og de spørger andre redditors “er det mig, der er røvhullet her?”. Det viser sig, at de fleste bliver bedømt som “ikke røvhullet”, som det fremgår af dette diagram:
Mit tweet med disse resultater fik en masse opmærksomhed:
Indtil spørgsmålet – er reddit pænere mod kvinder eller mod mænd?
Beslutning om køn
Hvis man kigger på titlen eller indholdet af et indlæg, kan man have svært ved at afgøre, om “jeg” er en mand eller en kvinde – men det er ret nemt at tælle antallet af “hun/han/hun/hendes/kæreste/kæreste”, der er til stede i historien.
Lad os se på nogle tilfældige indlæg, og tallet for hvert af disse pronominer og kønsord:

Vi kan se, at antallet af kønnede stedord og ord i eksemplet passer til, hvem historien handler om. Disse historier handler om en mandlig kunde, en kvindelig kæreste, en mandlig nabo, en mandlig søn og en kvindelig teenagedatter.
Med disse tal kan vi nu opstille en vilkårlig regel: Hvis der er mere end dobbelt så mange mandlige pronominer som kvindelige, handler indlægget om en mand. Vi kan bruge den modsatte regel til at sige, at indlægget handler om en kvinde. Hvis tallene ligger for tæt på hinanden eller er nul, kalder vi indlægget for “neutralt”.
En anden regel kan vi opstille for at forenkle analysen:
- Hvis bedømmelsen er “ikke a-hullet” eller “ingen a-huller her”, så kan vi sige “plakaten er ikke et røvhul”.
- Hvis dommen er ‘røvhul’ eller ‘alle er røvhuller’, så kan vi sige ‘plakaten er et røvhul’.
Hvis vi aggregerer alle disse indlæg, kommer vi frem til tallene:

Da jeg først præsenterede disse resultater, fik jeg at vide “disse tal er for tæt på, de kunne være en statistisk fejl”.
Statistisk signifikans?
Hvordan kan vi se, at tallene ikke blot er en statistisk fejl? Lad os se tendensen måned for måned – er den stabil?

Ja! Tendensen varierer fra måned til måned, men der er en klart større chance for at være et røvhul, når man taler om kvinder end når man taler om mænd. Hvis den lille forskel bare var en statistisk tilfældighed, ville vi forvente, at tendensen i stedet ville springe vildt i vejret.
Og bemærk venligst, at disse resultater er meget specifikke, som dette tweet bemærker:
Hvortil jeg svarede
How-to
Denne gang bruger jeg dbt for første gang, og jeg har efterladt al min kode på GitHub. Tak Claire Carroll for din hjælp til at komme i gang med dette fantastiske værktøj!
For at udtrække alle /r/AmItheAsshole-indlæggene i BigQuery til en ny tabel kan du gøre:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Så kan køn og bedømmelse for hvert indlæg bestemmes med en forespørgsel som:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
Og endelig de statistikker, der præsenteres her:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Diskussion
Du vil finde masser af indsigtsfulde og underholdende svar på twittertråden til dette indlæg:
Føler du dig velkommen til at deltage i diskussionen (og fortælle mig, hvis jeg tager fejl?). Husk at være søde ved hinanden – de fleste er ikke røvhuller alligevel.
Vil du have mere?
Jeg dækkede kun indtil august 2019, da det er der, hvor det nuværende fulde reddit-arkiv i BigQuery stopper – indtil fremtidige forventede opdateringer. Tjek mit tidligere indlæg for flere detaljer om indsamling af live-data fra pushshift.io. Tak Jason Baumgartner for den konstante forsyning!
Jeg hedder Felipe Hoffa og er Developer Advocate for Google Cloud. Følg mig på @felipehoffa, find mine tidligere indlæg på medium.com/@hoffa, og alt om BigQuery på reddit.com/r/bigquery.