Big Data und Hadoop Ökosystem Tutorial
Willkommen zur ersten Lektion ‚Big Data und Hadoop Ökosystem‘ des Big Data Hadoop Tutorials, das ein Teil des ‚Big Data Hadoop und Spark Developer Certification Kurses‘ ist, der von Simplilearn angeboten wird. Diese Lektion ist eine Einführung in Big Data und das Hadoop-Ökosystem. Im nächsten Abschnitt werden wir die Ziele dieser Lektion besprechen.
Ziele
Nach Abschluss dieser Lektion werden Sie in der Lage sein,:
-
Das Konzept von Big Data und seine Herausforderungen verstehen
-
Erläutern, was Big Data ist
-
Erläutern, was Hadoop ist und wie es die Herausforderungen von Big Data angeht
-
Beschreiben Sie das Hadoop-Ökosystem
Werfen wir nun einen Blick auf den Überblick über Big Data und Hadoop.
Überblick zu Big Data und Hadoop
Vor dem Jahr 2000 waren die Daten relativ klein, aber die Datenberechnung war komplex. Alle Datenberechnungen hingen von der Verarbeitungsleistung der verfügbaren Computer ab.
Später, als die Daten immer größer wurden, bestand die Lösung darin, Computer mit großem Speicher und schnellen Prozessoren einzusetzen. Nach dem Jahr 2000 wuchsen die Daten jedoch immer weiter an, und die ursprüngliche Lösung konnte nicht mehr helfen.
In den letzten Jahren ist das Datenvolumen explosionsartig angestiegen. IBM meldete, dass im Jahr 2012 täglich 2,5 Exabyte, d. h. 2,5 Milliarden Gigabyte an Daten erzeugt wurden.
Hier sind einige Statistiken, die die Vermehrung von Daten zeigen, aus Forbes, September 2015. Jede Sekunde werden 40.000 Suchanfragen bei Google durchgeführt. Jede Minute werden bis zu 300 Stunden Video auf YouTube hochgeladen.
In Facebook werden 31,25 Millionen Nachrichten von den Nutzern verschickt und 2,77 Millionen Videos werden jede Minute angesehen. Bis 2017 werden fast 80 % der Fotos mit Smartphones aufgenommen.
Bis 2020 wird mindestens ein Drittel aller Daten über die Cloud (ein Netz von Servern, die über das Internet verbunden sind) laufen. Bis zum Jahr 2020 werden für jeden Menschen auf der Erde jede Sekunde etwa 1,7 Megabyte an neuen Informationen entstehen.
Daten wachsen schneller als je zuvor. Sie können mehr Computer einsetzen, um diese ständig wachsenden Daten zu verwalten. Statt einer Maschine, die die Aufgabe erledigt, kann man mehrere Maschinen einsetzen. Dies wird als verteiltes System bezeichnet.
Die Vorschau auf den Big Data Hadoop and Spark Developer Certification Kurs finden Sie hier!
Schauen wir uns ein Beispiel an, um zu verstehen, wie ein verteiltes System funktioniert.
Wie funktioniert ein verteiltes System?
Angenommen, Sie haben eine Maschine, die vier Ein-/Ausgabekanäle hat. Die Geschwindigkeit jedes Kanals beträgt 100 MB/s, und Sie wollen ein Terabyte an Daten verarbeiten.
Eine Maschine braucht 45 Minuten, um ein Terabyte an Daten zu verarbeiten. Nehmen wir nun an, dass ein Terabyte Daten von 100 Rechnern mit der gleichen Konfiguration verarbeitet wird.
Es dauert nur 45 Sekunden, bis 100 Rechner ein Terabyte Daten verarbeitet haben. Verteilte Systeme benötigen weniger Zeit für die Verarbeitung von Big Data.
Werfen wir nun einen Blick auf die Herausforderungen eines verteilten Systems.
Herausforderungen verteilter Systeme
Da in einem verteilten System mehrere Computer verwendet werden, ist die Wahrscheinlichkeit eines Systemausfalls hoch. Auch die Bandbreite ist begrenzt.
Die Komplexität der Programmierung ist ebenfalls hoch, da es schwierig ist, Daten und Prozesse zu synchronisieren. Hadoop kann diese Herausforderungen bewältigen.
Im nächsten Abschnitt wird erläutert, was Hadoop ist.
Was ist Hadoop?
Hadoop ist ein Rahmenwerk, das die verteilte Verarbeitung großer Datenmengen über Computercluster mit einfachen Programmiermodellen ermöglicht. Es wurde von einem technischen Dokument inspiriert, das von Google veröffentlicht wurde.
Das Wort Hadoop hat keine Bedeutung. Doug Cutting, der Entdecker von Hadoop, benannte es nach dem gelben Spielzeugelefanten seines Sohnes.
Lassen Sie uns diskutieren, wie Hadoop die drei Herausforderungen des verteilten Systems löst, wie die hohe Wahrscheinlichkeit von Systemausfällen, die begrenzte Bandbreite und die Komplexität der Programmierung.
Die vier Hauptmerkmale von Hadoop sind:
-
Wirtschaftlich: Seine Systeme sind sehr wirtschaftlich, da normale Computer für die Datenverarbeitung verwendet werden können.
-
Zuverlässig: Es ist zuverlässig, da es Kopien der Daten auf verschiedenen Rechnern speichert und resistent gegen Hardware-Ausfälle ist.
-
Skalierbar: Es ist leicht skalierbar, sowohl horizontal als auch vertikal. Ein paar zusätzliche Knoten helfen bei der Skalierung des Frameworks.
-
Flexibel: Es ist flexibel und Sie können so viele strukturierte und unstrukturierte Daten speichern, wie Sie benötigen, und entscheiden, ob Sie sie später verwenden möchten.
Traditionell wurden Daten an einem zentralen Ort gespeichert und zur Laufzeit an den Prozessor gesendet. Diese Methode funktionierte gut für begrenzte Datenmengen.
Moderne Systeme erhalten jedoch täglich Terabytes an Daten, und es ist für herkömmliche Computer oder relationale Datenbankmanagementsysteme (RDBMS) schwierig, große Datenmengen an den Prozessor zu senden.
Hadoop brachte einen radikalen Ansatz. Bei Hadoop geht das Programm zu den Daten, nicht umgekehrt. Es verteilt die Daten zunächst auf mehrere Systeme und führt später die Berechnungen dort aus, wo sich die Daten befinden.
Im folgenden Abschnitt werden wir darüber sprechen, wie sich Hadoop vom traditionellen Datenbanksystem unterscheidet.
Unterschied zwischen traditionellem Datenbanksystem und Hadoop
Die folgende Tabelle hilft Ihnen, zwischen traditionellem Datenbanksystem und Hadoop zu unterscheiden.
|
Traditionelles Datenbanksystem |
Hadoop |
|
Daten werden an einem zentralen Ort gespeichert und zur Laufzeit an den Prozessor gesendet. |
In Hadoop geht das Programm zu den Daten. Es verteilt die Daten zunächst auf mehrere Systeme und führt später die Berechnungen dort aus, wo sich die Daten befinden. |
|
Traditionelle Datenbanksysteme können nicht verwendet werden, um große Datenmengen (Big Data) zu verarbeiten und zu speichern. |
Hadoop funktioniert besser, wenn die Datenmenge groß ist. Es kann eine große Datenmenge effizient und effektiv verarbeiten und speichern. |
|
Traditionelle RDBMS werden nur für die Verwaltung strukturierter und halbstrukturierter Daten verwendet. Es kann nicht verwendet werden, um unstrukturierte Daten zu verwalten. |
Hadoop kann eine Vielzahl von Daten verarbeiten und speichern, unabhängig davon, ob es sich um strukturierte oder unstrukturierte Daten handelt. |
Lassen Sie uns den Unterschied zwischen traditionellen RDBMS und Hadoop mit Hilfe einer Analogie erörtern.
Sie werden den Unterschied im Essverhalten eines Menschen und eines Tigers bemerkt haben. Ein Mensch isst mit Hilfe eines Löffels, wobei die Nahrung zum Mund geführt wird. Ein Tiger hingegen bringt sein Maul zum Essen.
Wenn nun das Essen Daten sind und das Maul ein Programm, dann stellt der Essstil des Menschen ein traditionelles RDBMS dar und der des Tigers ein Hadoop.
Lassen Sie uns im nächsten Abschnitt einen Blick auf das Hadoop-Ökosystem werfen.
Hadoop-Ökosystem
Hadoop-Ökosystem Hadoop verfügt über ein Ökosystem, das sich aus seinen drei Kernkomponenten Verarbeitung, Ressourcenmanagement und Speicherung entwickelt hat. In diesem Thema lernen Sie die Komponenten des Hadoop-Ökosystems kennen und erfahren, wie sie ihre Aufgaben bei der Verarbeitung von Big Data erfüllen. Das
Hadoop-Ökosystem wächst ständig, um den Anforderungen von Big Data gerecht zu werden. Es besteht aus den folgenden zwölf Komponenten:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
In den nächsten Abschnitten erfahren Sie mehr über die Rolle der einzelnen Komponenten des Hadoop-Ökosystems.

Lassen Sie uns die Rolle der einzelnen Komponenten des Hadoop-Ökosystems verstehen.
Komponenten des Hadoop-Ökosystems
Beginnen wir mit der ersten Komponente HDFS des Hadoop-Ökosystems.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS ist eine Speicherschicht für Hadoop.
-
HDFS eignet sich zur verteilten Speicherung und Verarbeitung, d.h. die Daten werden bei der Speicherung erst verteilt und dann verarbeitet.
-
HDFS bietet Streaming-Zugriff auf Dateisystemdaten.
-
HDFS bietet Dateiberechtigung und Authentifizierung.
-
HDFS verwendet eine Befehlszeilenschnittstelle, um mit Hadoop zu interagieren.
Was also speichert Daten in HDFS? Es ist die HBase, die Daten in HDFS speichert.
HBase
-
HBase ist eine NoSQL-Datenbank oder nicht-relationale Datenbank.
-
HBase ist wichtig und wird vor allem dann verwendet, wenn Sie zufälligen, Echtzeit-, Lese- oder Schreibzugriff auf Ihre Big Data benötigen.
-
Sie unterstützt ein hohes Datenvolumen und einen hohen Durchsatz.
-
In einer HBase kann eine Tabelle Tausende von Spalten haben.
Wir haben besprochen, wie die Daten verteilt und gespeichert werden. Nun wollen wir verstehen, wie diese Daten in das HDFS aufgenommen oder übertragen werden. Sqoop macht genau das.
Was ist Sqoop?
-
Sqoop ist ein Tool, das für die Datenübertragung zwischen Hadoop und relationalen Datenbankservern entwickelt wurde.
-
Es wird verwendet, um Daten aus relationalen Datenbanken (wie Oracle und MySQL) in HDFS zu importieren und Daten aus HDFS in relationale Datenbanken zu exportieren.
Wenn Sie Ereignisdaten wie Streaming-Daten, Sensordaten oder Protokolldateien einlesen möchten, können Sie Flume verwenden. Wir werden uns Flume im nächsten Abschnitt ansehen.
Flume
-
Flume ist ein verteilter Dienst, der Ereignisdaten sammelt und in das HDFS überträgt.
-
Es ist ideal für Ereignisdaten aus mehreren Systemen geeignet.
Nachdem die Daten in das HDFS übertragen wurden, werden sie verarbeitet. Eines der Frameworks, die Daten verarbeiten, ist Spark.
Was ist Spark?
-
Spark ist ein Open-Source-Cluster-Computing-Framework.
-
Es bietet eine bis zu 100-mal schnellere Leistung für einige wenige Anwendungen mit In-Memory-Primitiven im Vergleich zum zweistufigen, festplattenbasierten MapReduce-Paradigma von Hadoop.
-
Spark kann im Hadoop-Cluster laufen und Daten im HDFS verarbeiten.
-
Es unterstützt auch eine Vielzahl von Workloads, darunter maschinelles Lernen, Business Intelligence, Streaming und Batch-Verarbeitung.
Spark hat die folgenden Hauptkomponenten:
-
Spark Core und Resilient Distributed Datasets oder RDD
-
Spark SQL
-
Spark Streaming
-
Machine Learning Library oder Mlib
-
Graphx.
Spark ist inzwischen weit verbreitet, und Sie werden in den folgenden Lektionen mehr darüber erfahren.
Hadoop MapReduce
-
Hadoop MapReduce ist das andere Framework, das Daten verarbeitet.
-
Es ist die ursprüngliche Hadoop-Verarbeitungs-Engine, die hauptsächlich auf Java basiert.
-
Es basiert auf dem Map- und Reduce-Programmiermodell.
-
Viele Tools wie Hive und Pig basieren auf einem Map-Reduce-Modell.
-
Es verfügt über eine umfangreiche und ausgereifte Fehlertoleranz, die in das Framework integriert ist.
-
Es wird immer noch sehr häufig verwendet, verliert aber gegenüber Spark an Boden.
Nach der Verarbeitung der Daten werden diese analysiert. Dies kann mit einem Open-Source-High-Level-Datenflusssystem namens Pig erfolgen. Es wird hauptsächlich für Analysen verwendet.
Lassen Sie uns nun verstehen, wie Pig für Analysen verwendet wird.
Pig
-
Pig wandelt seine Skripte in Map- und Reduce-Code um und erspart so dem Benutzer das Schreiben komplexer MapReduce-Programme.
-
Ad-hoc-Abfragen wie Filter und Join, die in MapReduce schwierig auszuführen sind, können mit Pig leicht durchgeführt werden.
-
Sie können Impala auch zur Datenanalyse verwenden.
-
Es handelt sich um eine Open-Source-Hochleistungs-SQL-Engine, die auf dem Hadoop-Cluster läuft.
-
Sie ist ideal für interaktive Analysen und hat eine sehr geringe Latenz, die in Millisekunden gemessen werden kann.
Impala
-
Impala unterstützt einen SQL-Dialekt, so dass Daten im HDFS wie eine Datenbanktabelle modelliert werden.
-
Sie können Datenanalysen auch mit HIVE durchführen. Es ist eine Abstraktionsschicht über Hadoop.
-
Es ist Impala sehr ähnlich. Es wird jedoch für die Datenverarbeitung und Extract-Transform-Load-Operationen, auch als ETL bekannt, bevorzugt.
-
Impala wird für Ad-hoc-Abfragen bevorzugt.
HIVE
-
HIVE führt Abfragen unter Verwendung von MapReduce aus; der Benutzer muss jedoch keinen Code in Low-Level-MapReduce schreiben.
-
Hive ist für strukturierte Daten geeignet. Nachdem die Daten analysiert wurden, stehen sie den Nutzern zur Verfügung.
Nachdem wir nun wissen, was HIVE leistet, werden wir erörtern, was die Suche nach Daten unterstützt. Die Datensuche erfolgt mit Cloudera Search.
Cloudera Search
-
Search ist eines der Produkte von Cloudera für den echtzeitnahen Zugriff. Es ermöglicht nicht-technischen Anwendern das Durchsuchen und Erforschen von Daten, die in Hadoop und HBase gespeichert sind oder in diese aufgenommen wurden.
-
Benutzer benötigen keine SQL- oder Programmierkenntnisse, um Cloudera Search zu verwenden, da es eine einfache Volltext-Schnittstelle für die Suche bietet.
-
Ein weiterer Vorteil von Cloudera Search im Vergleich zu eigenständigen Suchlösungen ist die vollständig integrierte Datenverarbeitungsplattform.
-
Cloudera Search nutzt das flexible, skalierbare und robuste Speichersystem, das in CDH oder der Cloudera-Distribution, einschließlich Hadoop, enthalten ist. Damit entfällt die Notwendigkeit, große Datensätze über verschiedene Infrastrukturen hinweg zu verschieben, um Geschäftsaufgaben zu bewältigen.
-
Hadoop-Jobs wie MapReduce, Pig, Hive und Sqoop verfügen über Workflows.
Oozie
-
Oozie ist ein Workflow- oder Koordinationssystem, mit dem Sie Hadoop-Jobs verwalten können.
Der Lebenszyklus einer Oozie-Anwendung ist im folgenden Diagramm dargestellt.
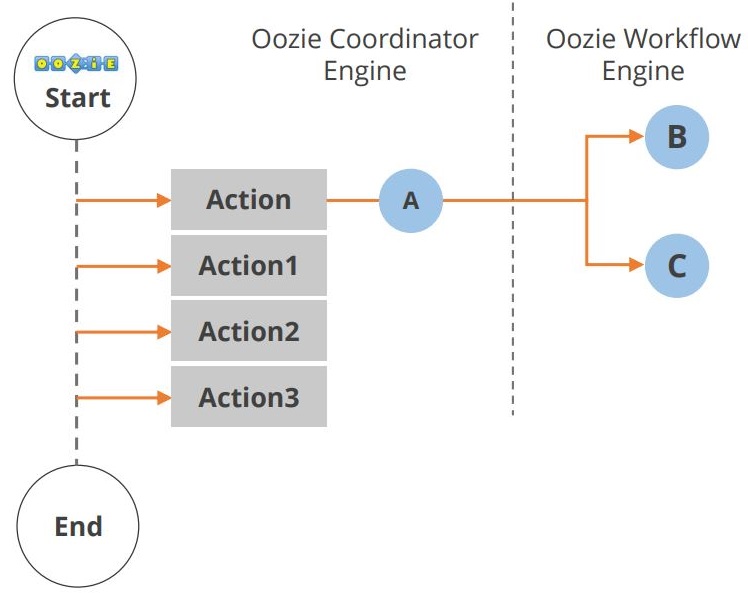 Wie Sie sehen, finden zwischen dem Start und dem Ende des Workflows mehrere Aktionen statt. Eine weitere Komponente im Hadoop-Ökosystem ist Hue. Schauen wir uns nun Hue an.
Wie Sie sehen, finden zwischen dem Start und dem Ende des Workflows mehrere Aktionen statt. Eine weitere Komponente im Hadoop-Ökosystem ist Hue. Schauen wir uns nun Hue an.
Hue
Hue ist ein Akronym für Hadoop User Experience. Es handelt sich um eine Open-Source-Webschnittstelle für Hadoop. Mit Hue können Sie folgende Operationen durchführen:
-
Daten hochladen und durchsuchen
-
Tabellen in HIVE und Impala abfragen
-
Spark- und Pig-Jobs und -Workflows ausführen Daten durchsuchen
-
Insgesamt macht Hue die Nutzung von Hadoop einfacher.
-
Es bietet auch einen SQL-Editor für HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL und Solr SQL.
Nach diesem kurzen Überblick über die zwölf Komponenten des Hadoop-Ökosystems werden wir nun erörtern, wie diese Komponenten zusammenarbeiten, um Big Data zu verarbeiten.
Stufen der Big Data-Verarbeitung
Es gibt vier Stufen der Big Data-Verarbeitung: Ingest, Processing, Analyze, Access. Schauen wir sie uns im Detail an.
Ingest
Die erste Stufe der Big-Data-Verarbeitung ist der Ingest. Die Daten werden aus verschiedenen Quellen wie relationalen Datenbanken, Systemen oder lokalen Dateien in Hadoop eingespeist oder dorthin übertragen. Sqoop überträgt Daten aus RDBMS an HDFS, während Flume Ereignisdaten überträgt.
Verarbeitung
Die zweite Stufe ist die Verarbeitung. In dieser Phase werden die Daten gespeichert und verarbeitet. Die Daten werden im verteilten Dateisystem HDFS und in der verteilten NoSQL-Datenbank HBase gespeichert. Spark und MapReduce führen die Datenverarbeitung durch.
Analysieren
Die dritte Stufe ist das Analysieren. Hier werden die Daten von Verarbeitungsframeworks wie Pig, Hive und Impala analysiert.
Pig konvertiert die Daten mithilfe von Map und Reduce und analysiert sie dann. Hive basiert ebenfalls auf der Map- und Reduce-Programmierung und eignet sich am besten für strukturierte Daten.
Access
Die vierte Stufe ist Access, die von Tools wie Hue und Cloudera Search durchgeführt wird. In dieser Phase können die Benutzer auf die analysierten Daten zugreifen.
Hue ist die Weboberfläche, während Cloudera Search eine Textschnittstelle für die Erkundung der Daten bereitstellt.
Hier finden Sie den Big Data Hadoop and Spark Developer Certification Kurs!
Zusammenfassung
Lassen Sie uns nun zusammenfassen, was wir in dieser Lektion gelernt haben.
-
Hadoop ist ein Framework für verteilte Speicherung und Verarbeitung.
-
Zu den Kernkomponenten von Hadoop gehören HDFS für die Speicherung, YARN für die Cluster-Ressourcenverwaltung und MapReduce oder Spark für die Verarbeitung.
-
Das Hadoop-Ökosystem umfasst mehrere Komponenten, die jede Stufe der Big-Data-Verarbeitung unterstützen.
-
Flume und Sqoop nehmen Daten auf, HDFS und HBase speichern Daten, Spark und MapReduce verarbeiten Daten, Pig, Hive und Impala analysieren Daten, Hue und Cloudera Search helfen, Daten zu erforschen.
-
Oozie verwaltet den Workflow von Hadoop-Jobs.
Abschluss
Damit ist die Lektion über Big Data und das Hadoop-Ökosystem abgeschlossen. In der nächsten Lektion werden wir HDFS und YARN besprechen.
Finden Sie unsere Big Data Hadoop und Spark Developer Online Classroom Schulungen in den größten Städten:
| Name | Datum | Ort | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3 Apr -15 Mai 2021, Wochenende | Ihre Stadt | Details ansehen |
| Big Data Hadoop and Spark Developer | 12 Apr -4 Mai 2021, Wochentags Batch | Ihre Stadt | Details anzeigen |
| Big Data Hadoop and Spark Developer | 24 Apr -5 Jun 2021, Weekend batch | Your City | View Details |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Um mehr zu erfahren, besuchen Sie den Kurs
Big Data Hadoop and Spark Developer Certification Training
Go to Course
Um mehr zu erfahren, besuchen Sie den Kurs
Big Data Hadoop and Spark Developer Certification Training Gehe zu Kurs